[1] 12Introdução à Modelos Estatísticos no R
Análise de dados univariados
Teste t
15 de maio de 2023
Maurício Vancine
Análises Ecológicas no R (2022)

15 capítulos: perguntas em ecologia, linguagem R, tidyverse, análises univariadas, multivariadas e geoespaciais
IMPORTANTE!!!
Estamos num espaço seguro e amigável
Sintam-se à vontade para me interromper e tirar dúvidas

Definição
O R é uma linguagem de programação livre (open source), direcionada à manipulação, análise e visualização de dados, com diversas expansões (pacotes) para dados ou análises específicas
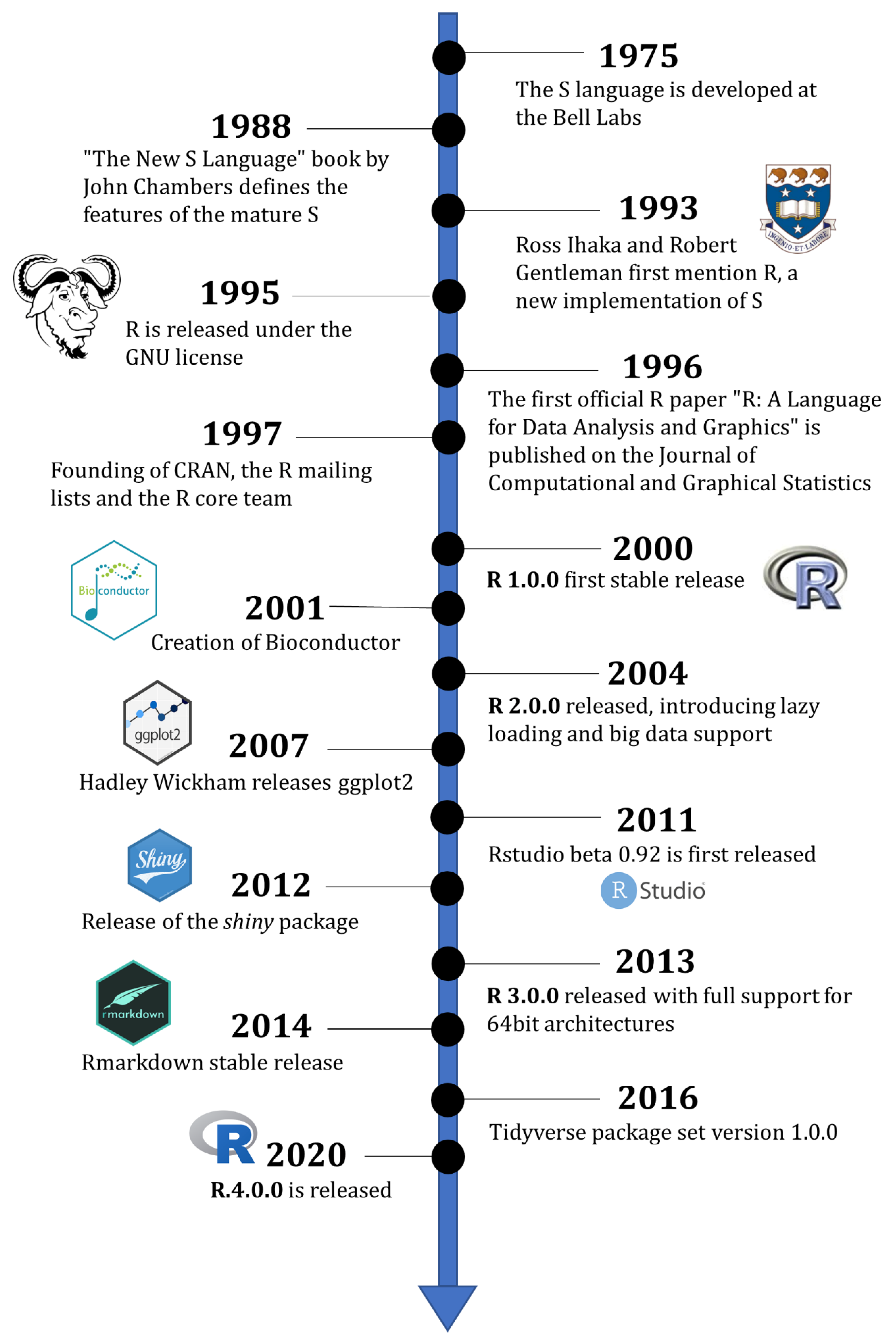
Histórico - Linguagem S
John M. Chambers (Stanford University, CA, EUA)
Versões
- Old S (1976-1987)
- New S (1988-1997)
- S4 (1998)
IDE (Integrated Development Environment)
- Interface: S-PLUS (1988-2008)

Histórico - Linguagem R
Robert Gentleman e Ross Ihaka (Auckland University, NZ)
Versões
- Desenvolvimento (1993-2000)
- Versão 1 (2000-2004)
- Versão 2 (2004-2013)
- Versão 3 (2013-2020)
- Versão 4 (2020-atual)
IDE (Integrated Development Environment)
- Interface: RStudio (2011-atual)
- Atualmente: R Core Team

Histórico - Linguagem R
Aplicações
Manipulação, visualização e análise de dados
- Estatísticas univariadas e multivariadas
- Análises de dados ecológicos
- Análise de dados espaciais, temporais e sonoros
- Análise de dados funcionais, genéticos e filogenéticos
- Análise de dados geoespaciais e sensoriamento remoto
- Visualização de todos os tipos de dados anteriores
R Markdown e quarto
- Textos em HTML, PDF, Word, ODT, Markdown
- Slides, Websites, Blogs, Livros e Artigos
- Shiny

IDE
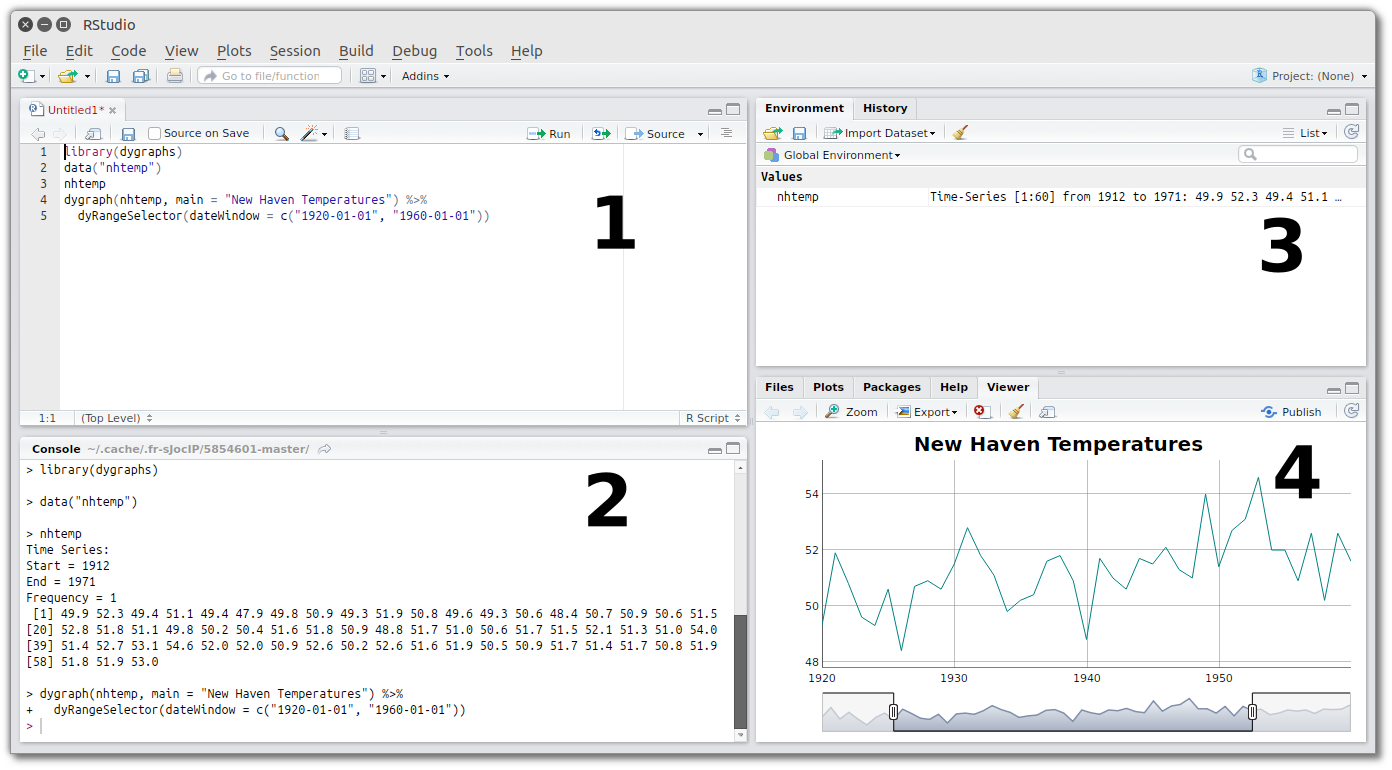
Ambiente de Desenvolvimento Integrado (Integrated Development Environment)
IDE
Ambiente de Desenvolvimento Integrado (Integrated Development Environment)


Interface
Projeto R (.Rproj)
- Facilita o trabalho em múltiplos ambientes
- Cada projeto possui seu diretório, documentos e workspace
- Permite controle de versão (git e GitHub)
Conferindo os computadores

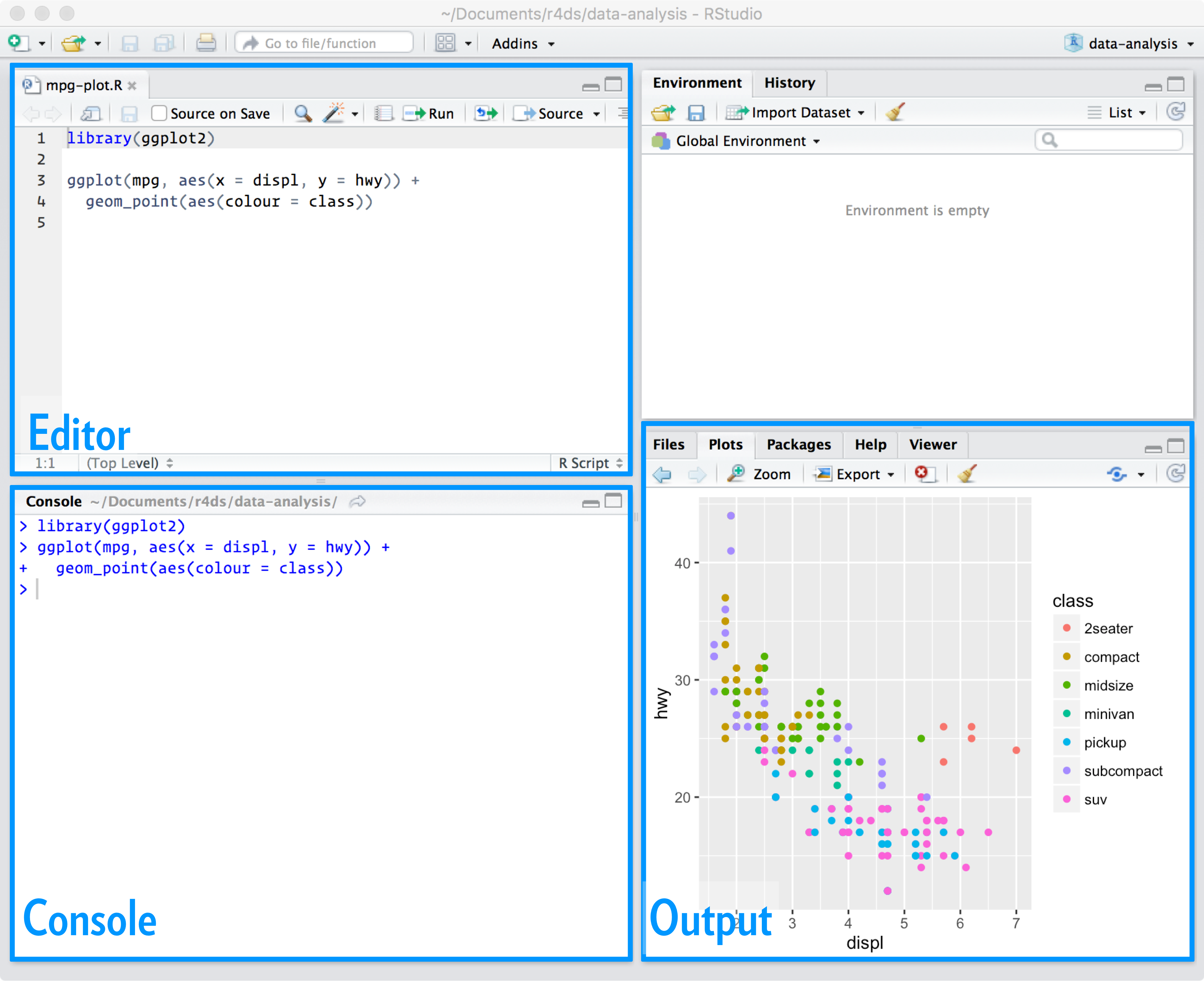
Console
O console é onde a linguagem R instalada é carregada para executar os códigos
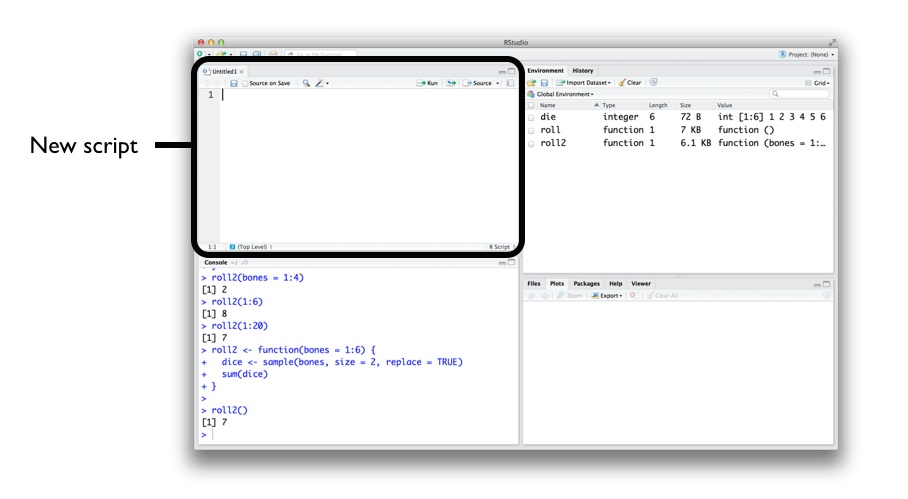
Script
Onde os códigos são escritos e salvos no formato .R
- Atalho:
ctrl + shift + N
Script
Salvar um script
- Atalho:
ctrl + S

Objetos
Palavras que atribuímos (guardamos) dados possibilitando sua manipulação
Atribuição (
<-)palavra <- dados
Atalho:
alt + -


Objetos
Ambiente (Environment)
Os objetos podem ser visualizados no painel Environment
Objetos
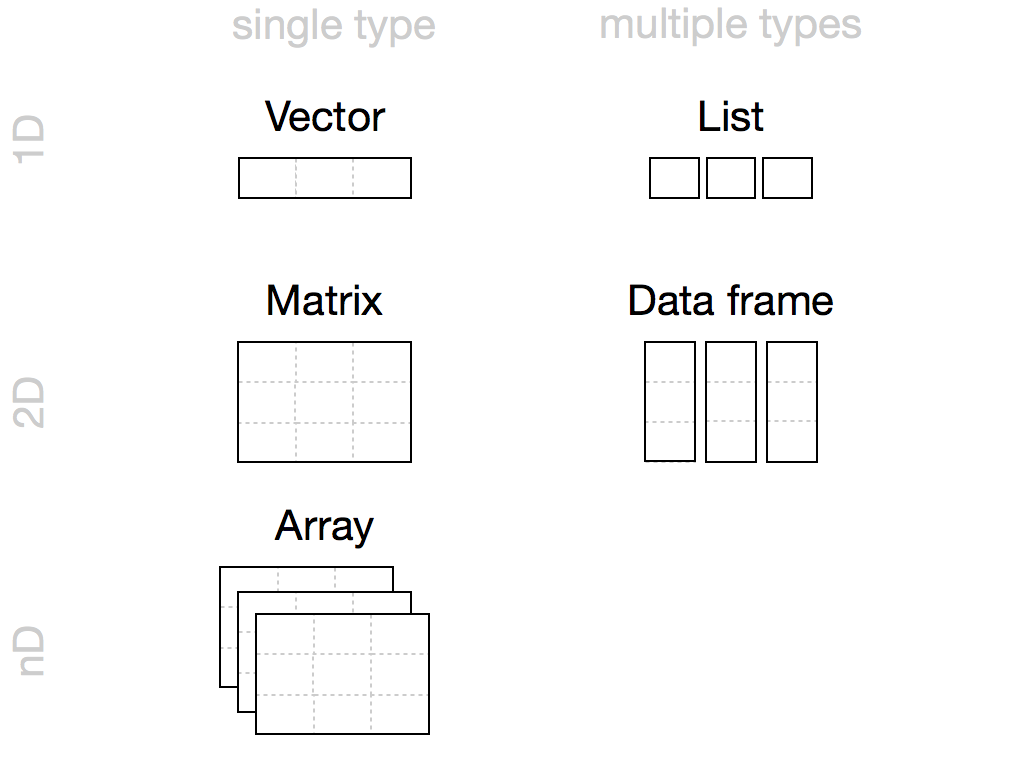
Tipos de objetos
Funções
Códigos que realizam operações em argumentos
- Estrutura de uma função:
nome_da_funcao(argumento1, argumento2)
- Nome da função: remete ao que ela faz (inglês)
- Parênteses: limitam a função
- Argumentos: onde a função atuará
- Vírgulas: separam os argumentos

Ajuda
Descreve as informações de uma função
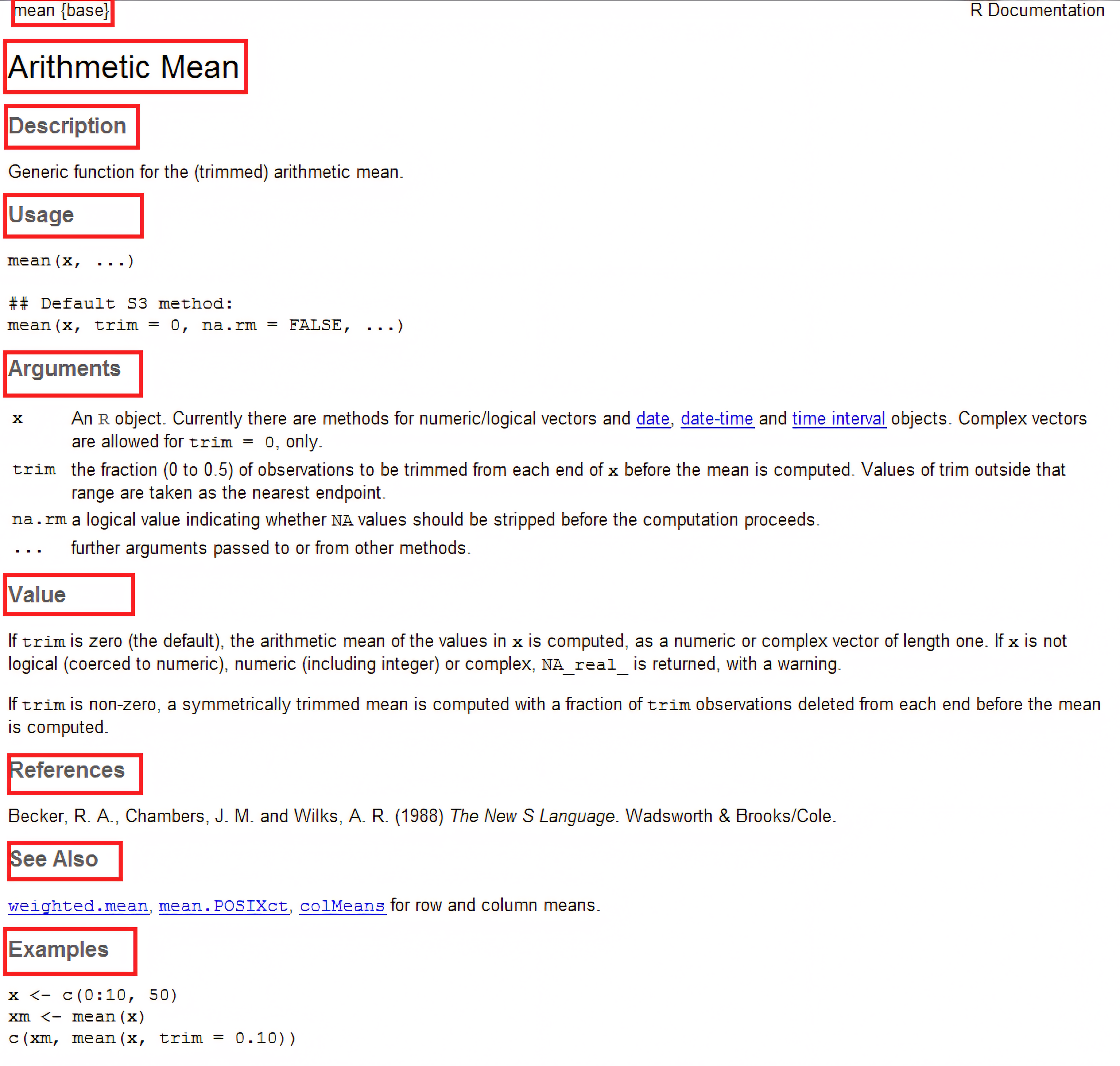
Description: descrição da função
Usage: uso da função e argumentos
Arguments: argumentos e suas especificações
Details: detalhes da função
Value: interpretar a saída (output)
Note: notas sobre a função
Authors: autores da função
References: referências bibliográficas da função
See also: funções relacionadas
Examples: exemplos do uso da função
Pacotes
Conjunto de funções extras para executar tarefas específicas

Pacotes
Duas fontes
- CRAN (Comprehensive R Archive Network)
- GitHub (Repositório de códigos)



Help me help you: um bestiário para entender erros e pedir ajuda no R

Como mentir com estatística?

Elementos de um gráfico
Representações das colunas (eixos) e linhas (elementos)
Tipos de variáveis
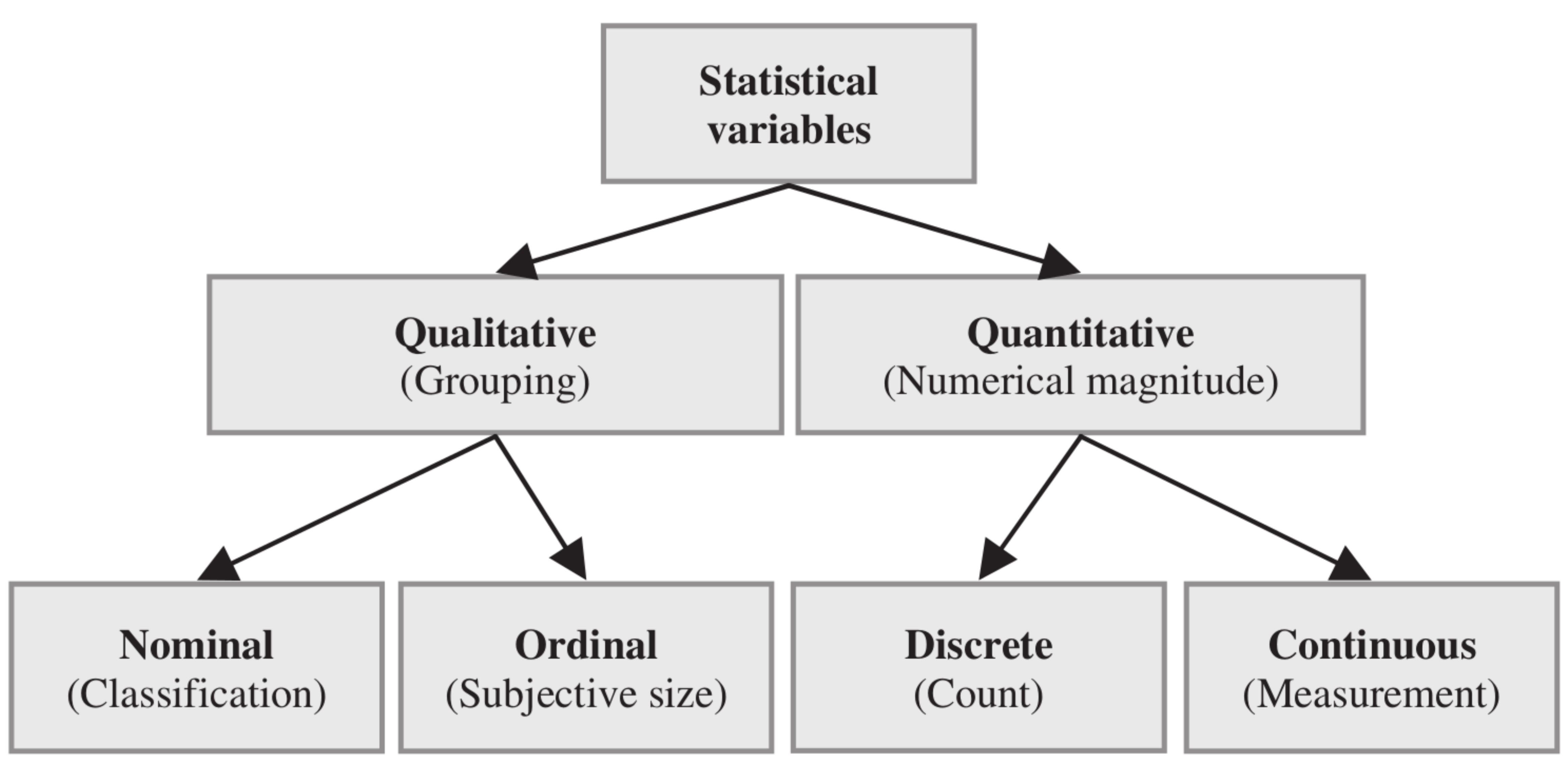

Tipos de variáveis e tipos gráficos
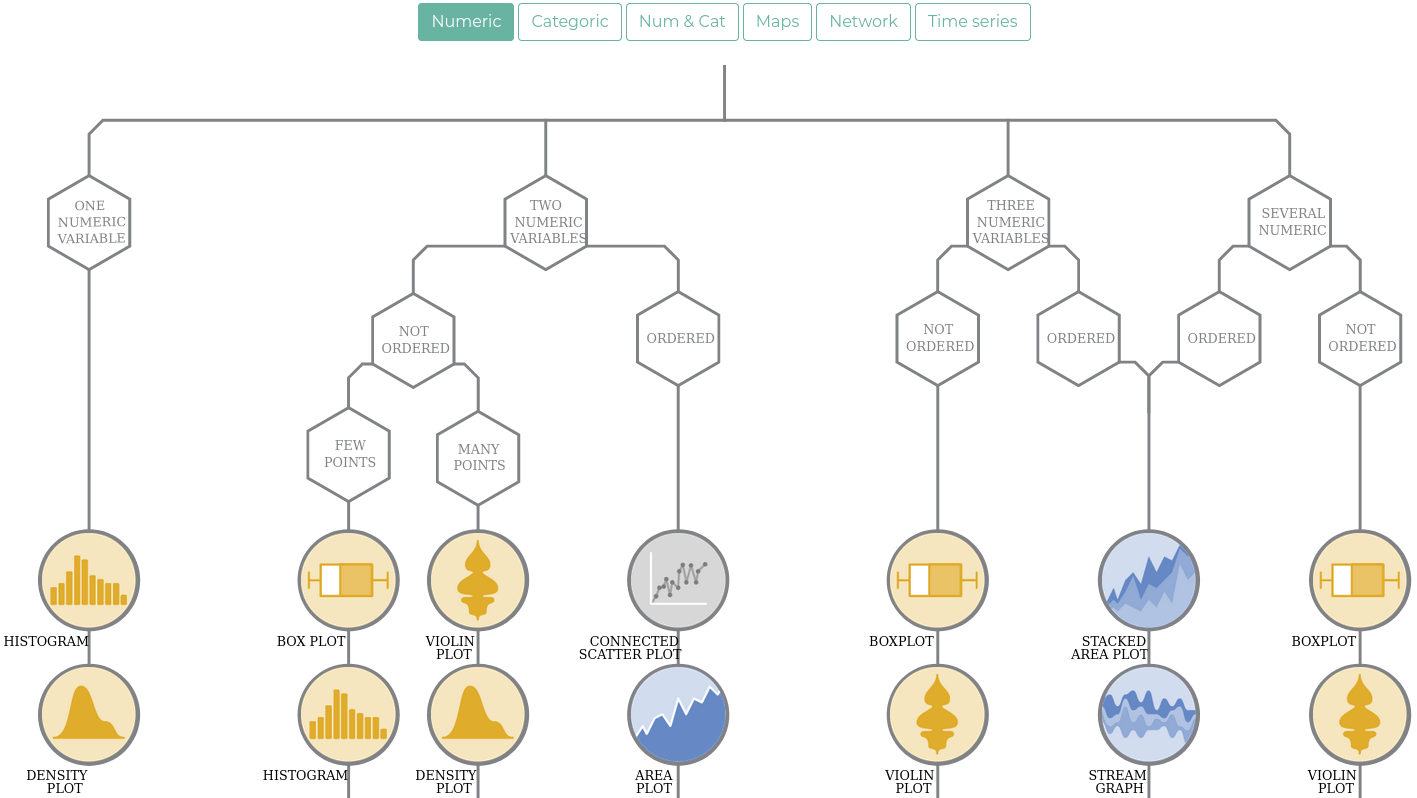
Tipos de variáveis e tipos gráficos
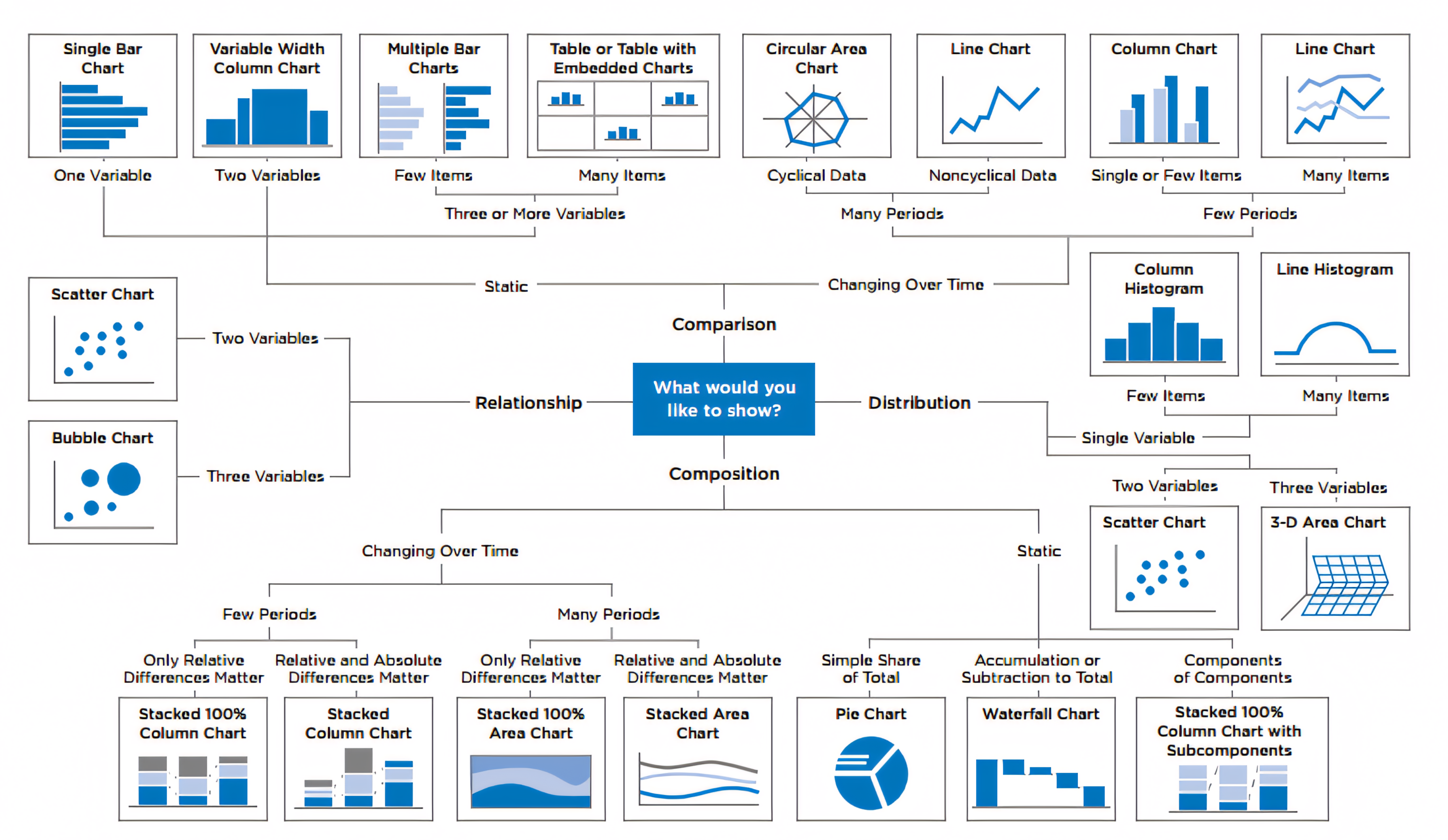
R CHARTS
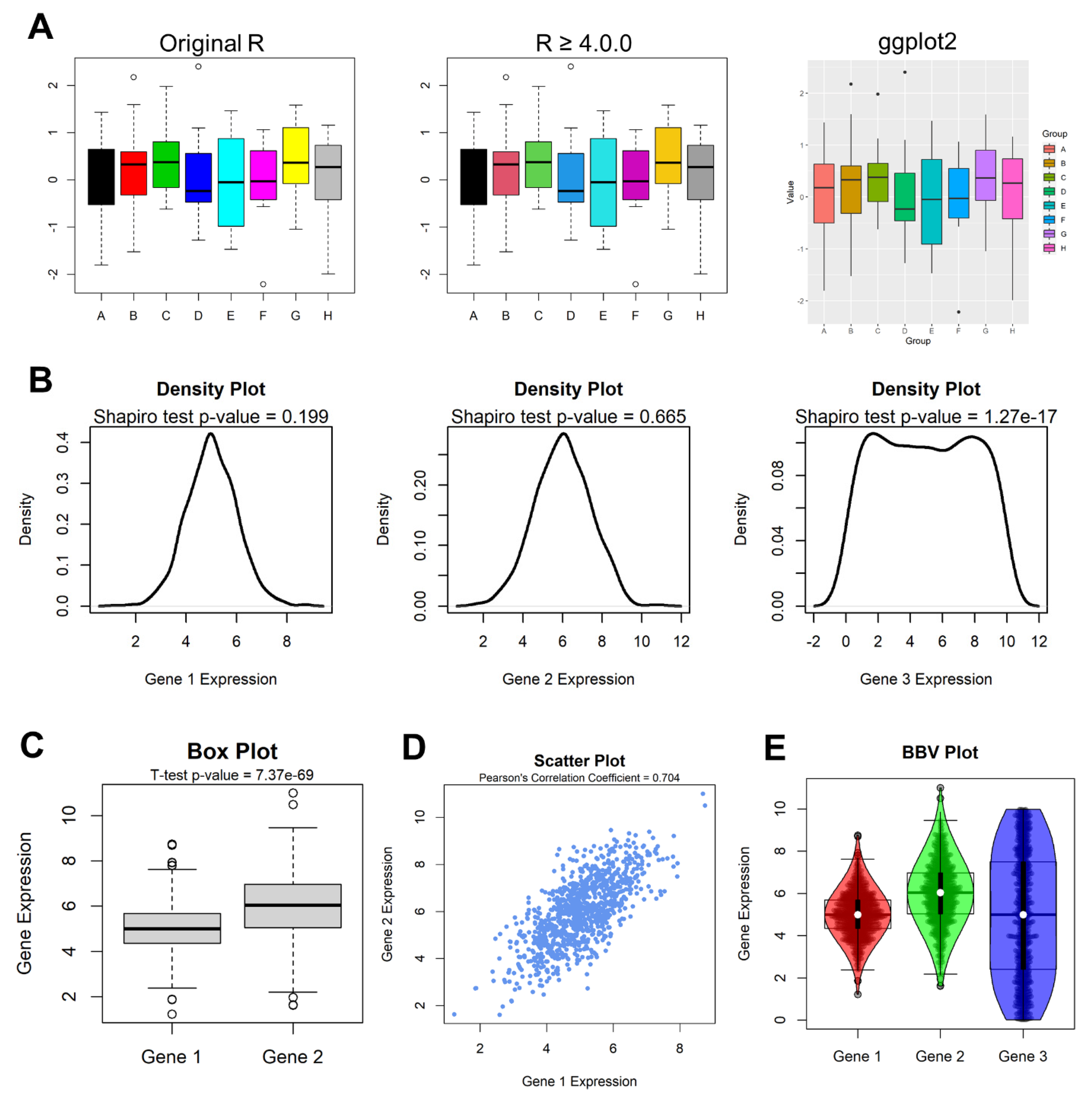
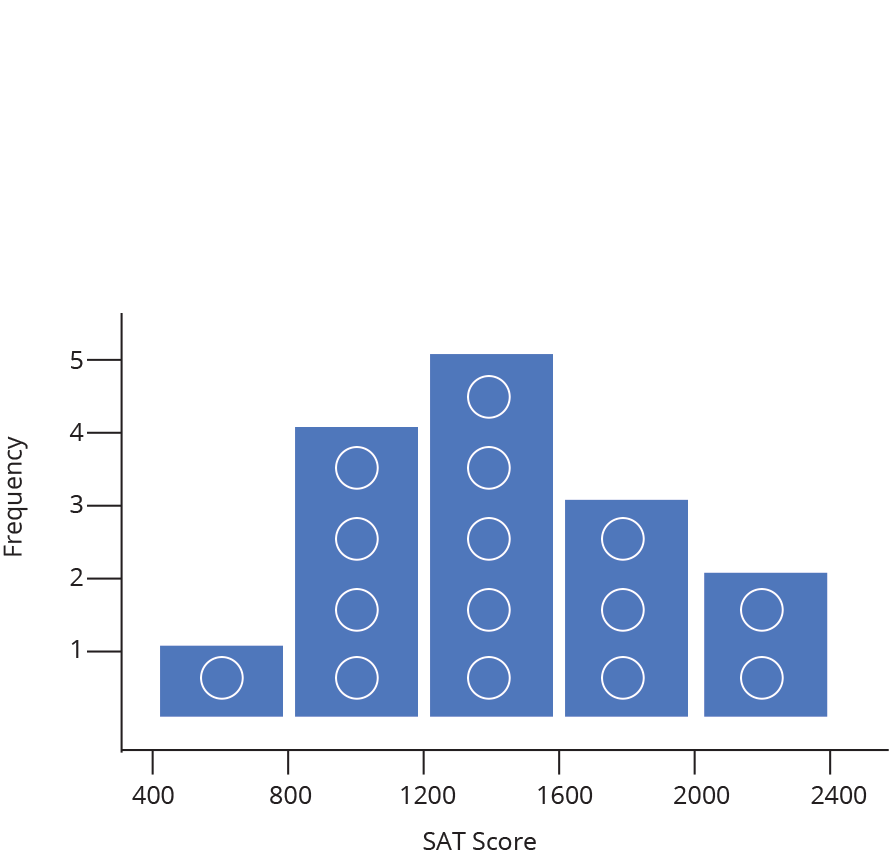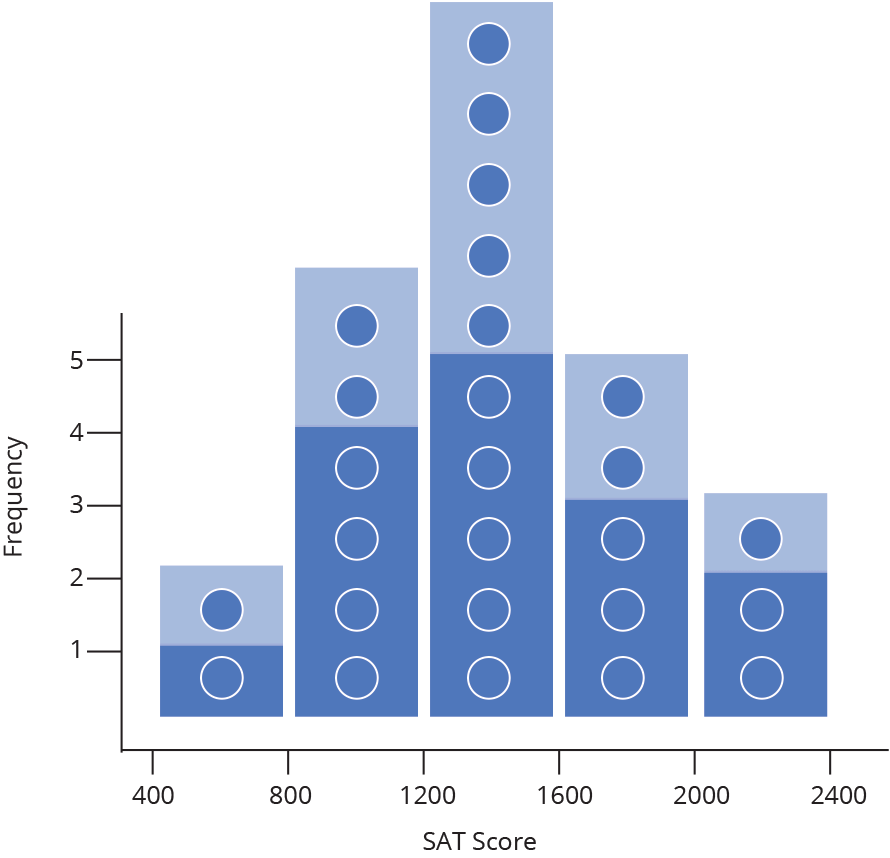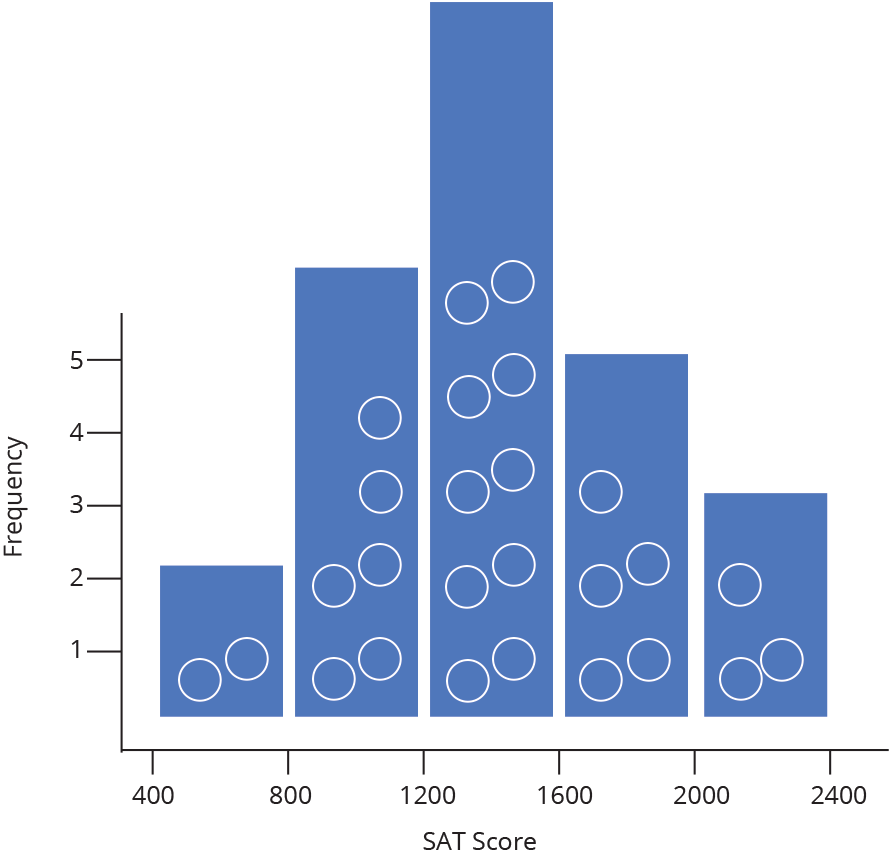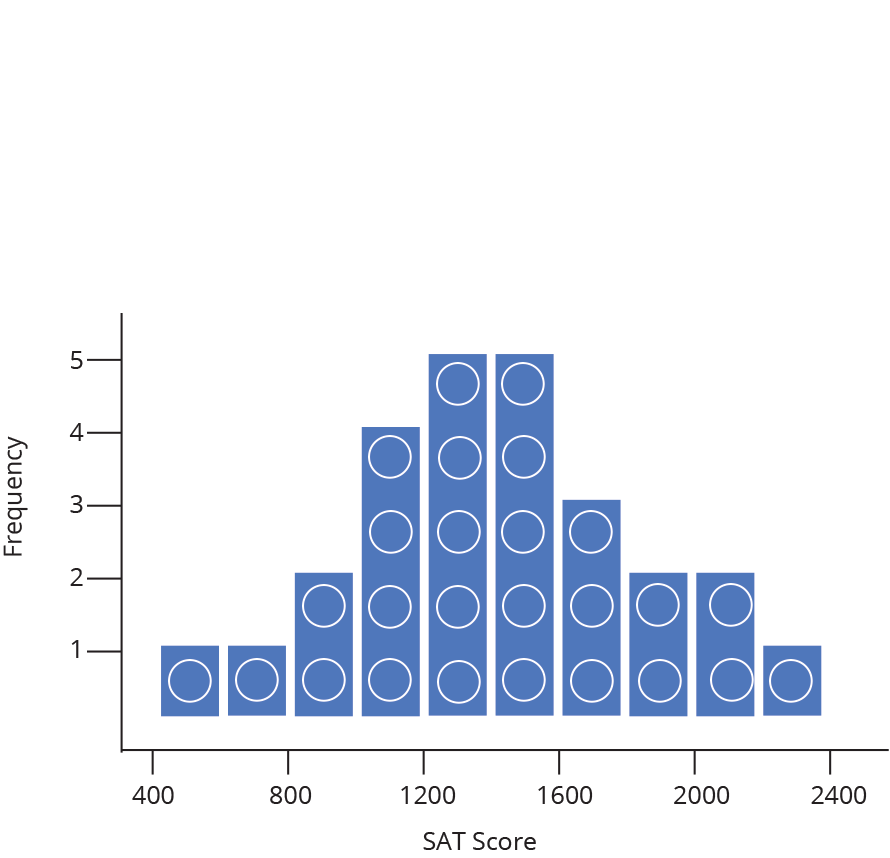
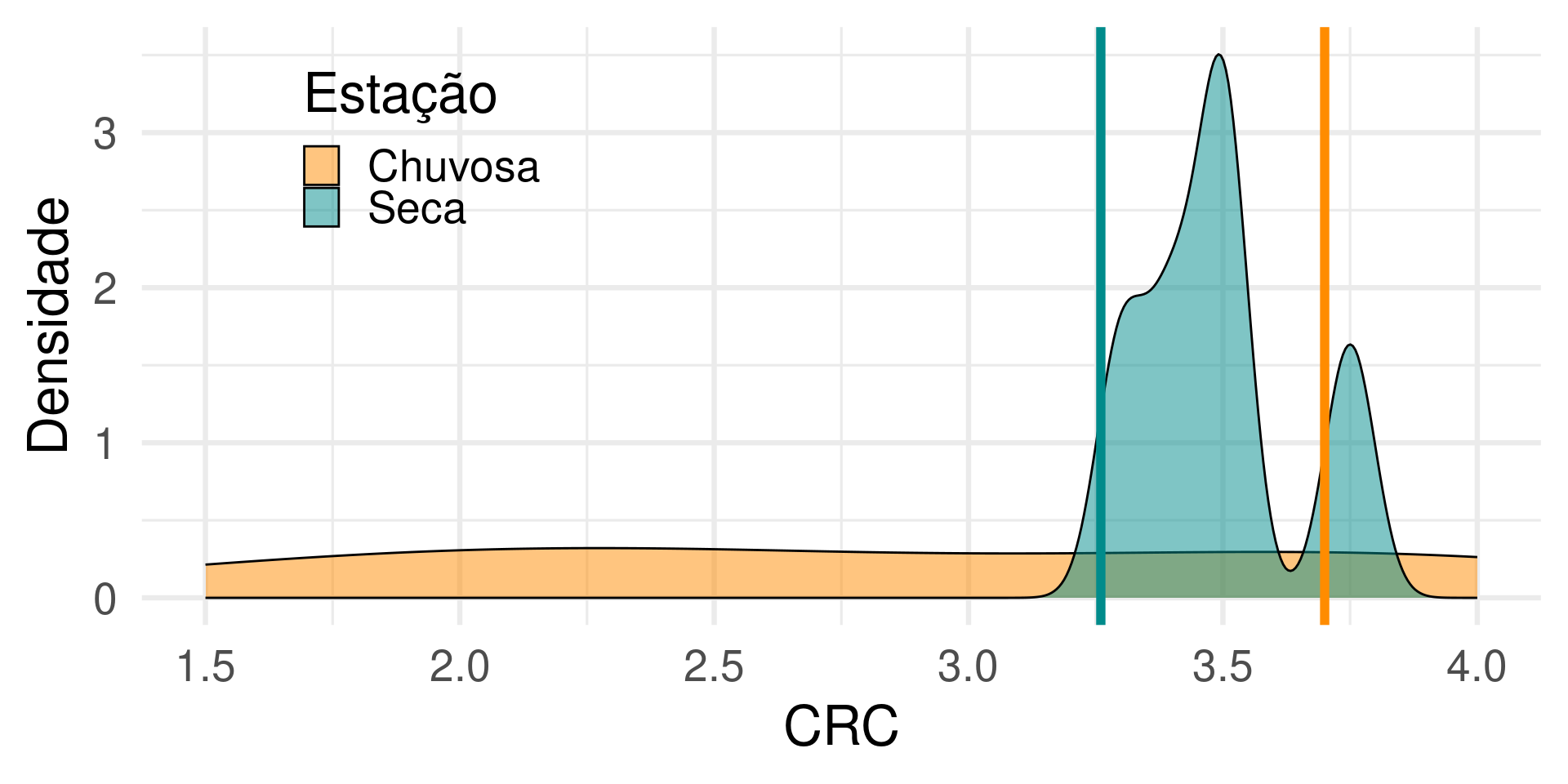
Histograma ou densidade
Representa dados de uma coluna
Dados do tipo discreto ou contínuo
Distribuição de frequência ou densidade
Histograma

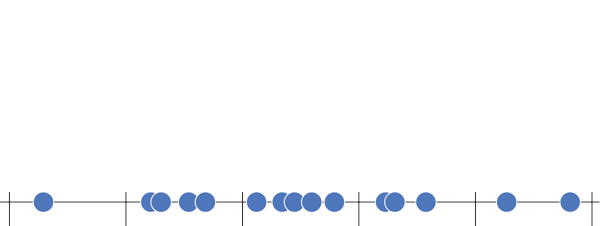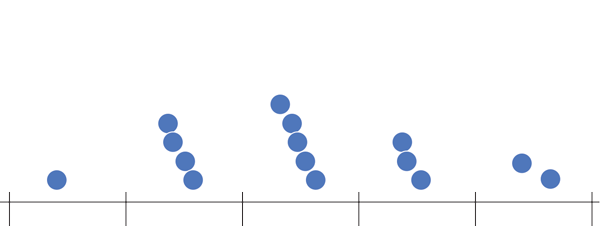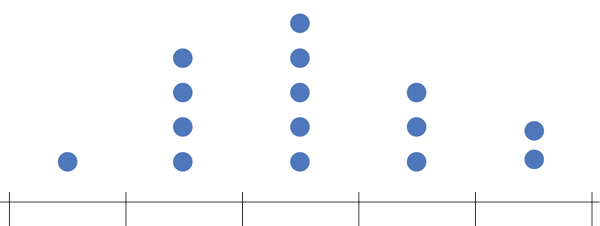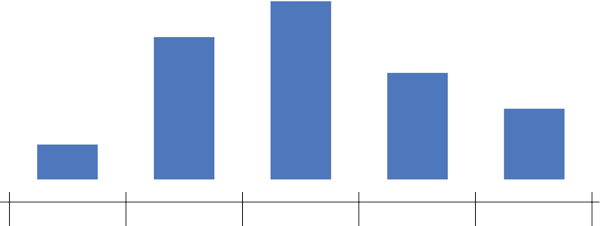
Histograma
Densidade
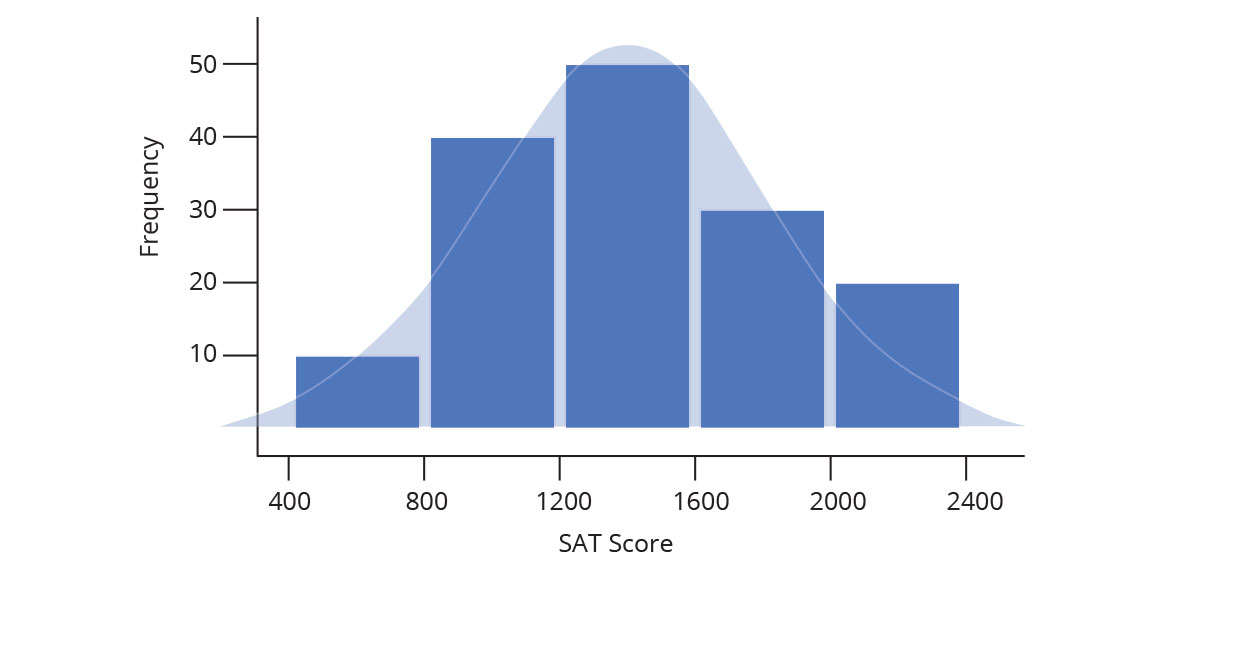
Densidade
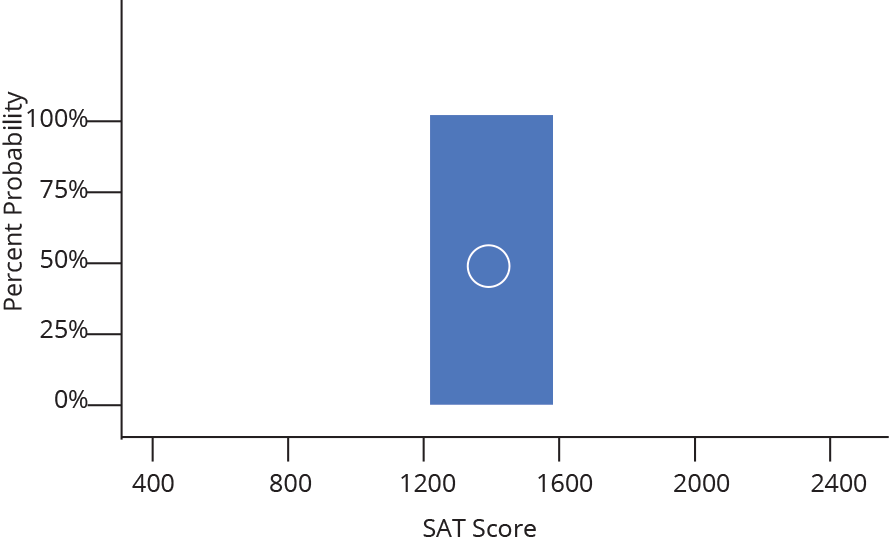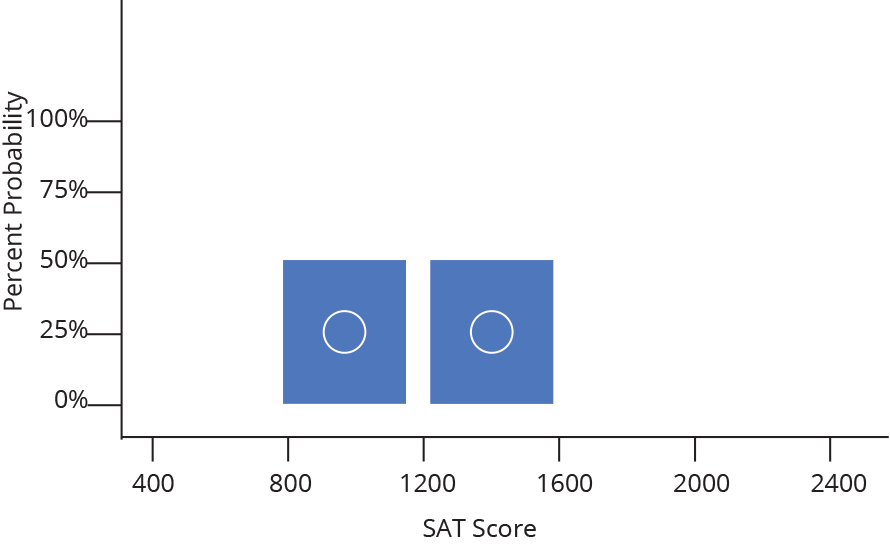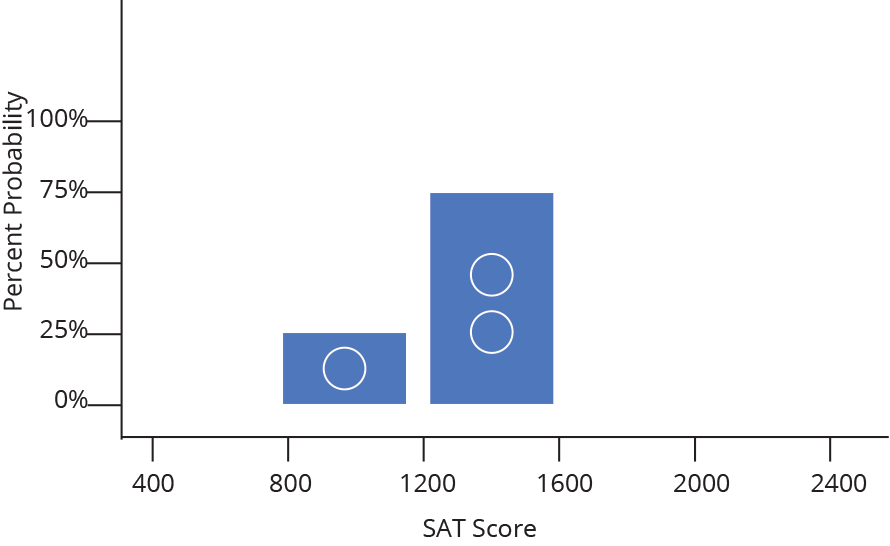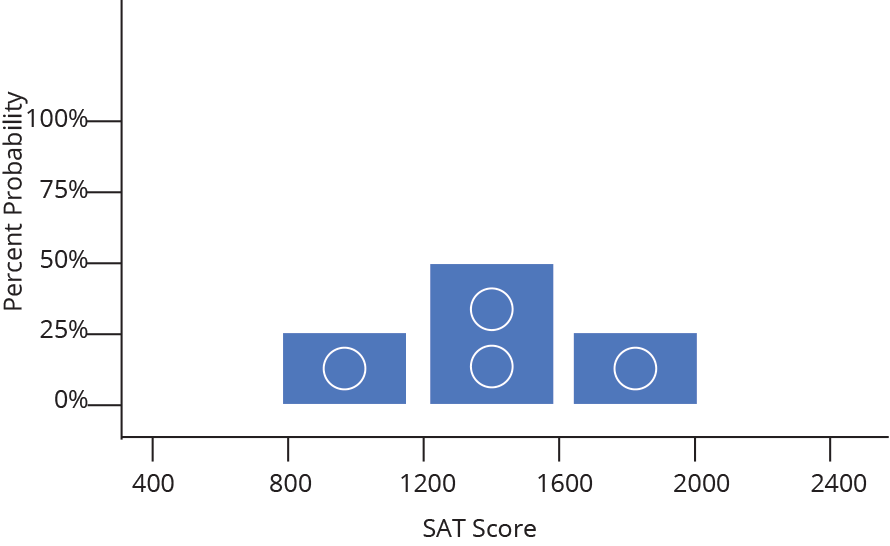
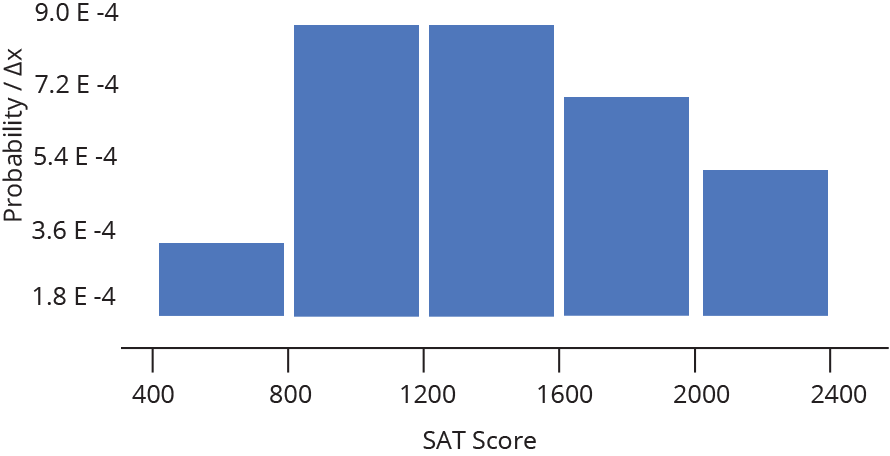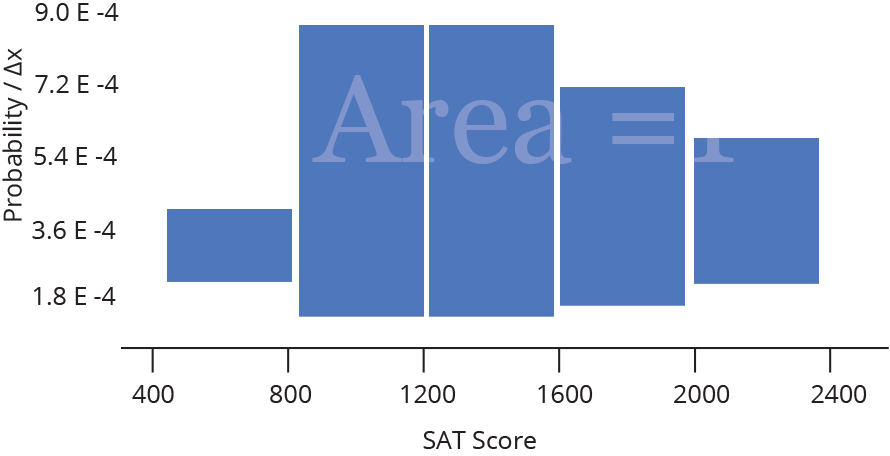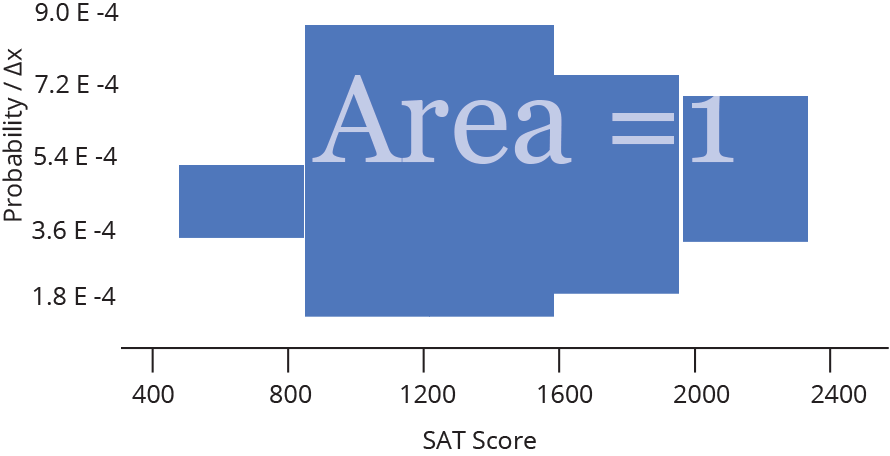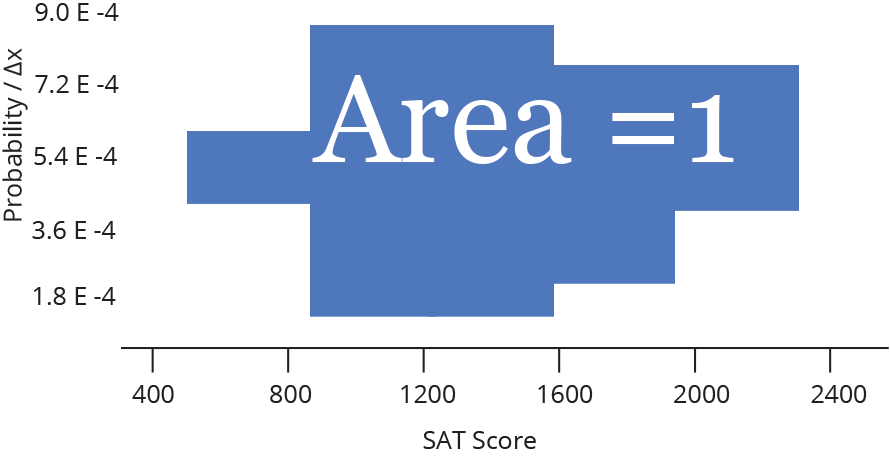
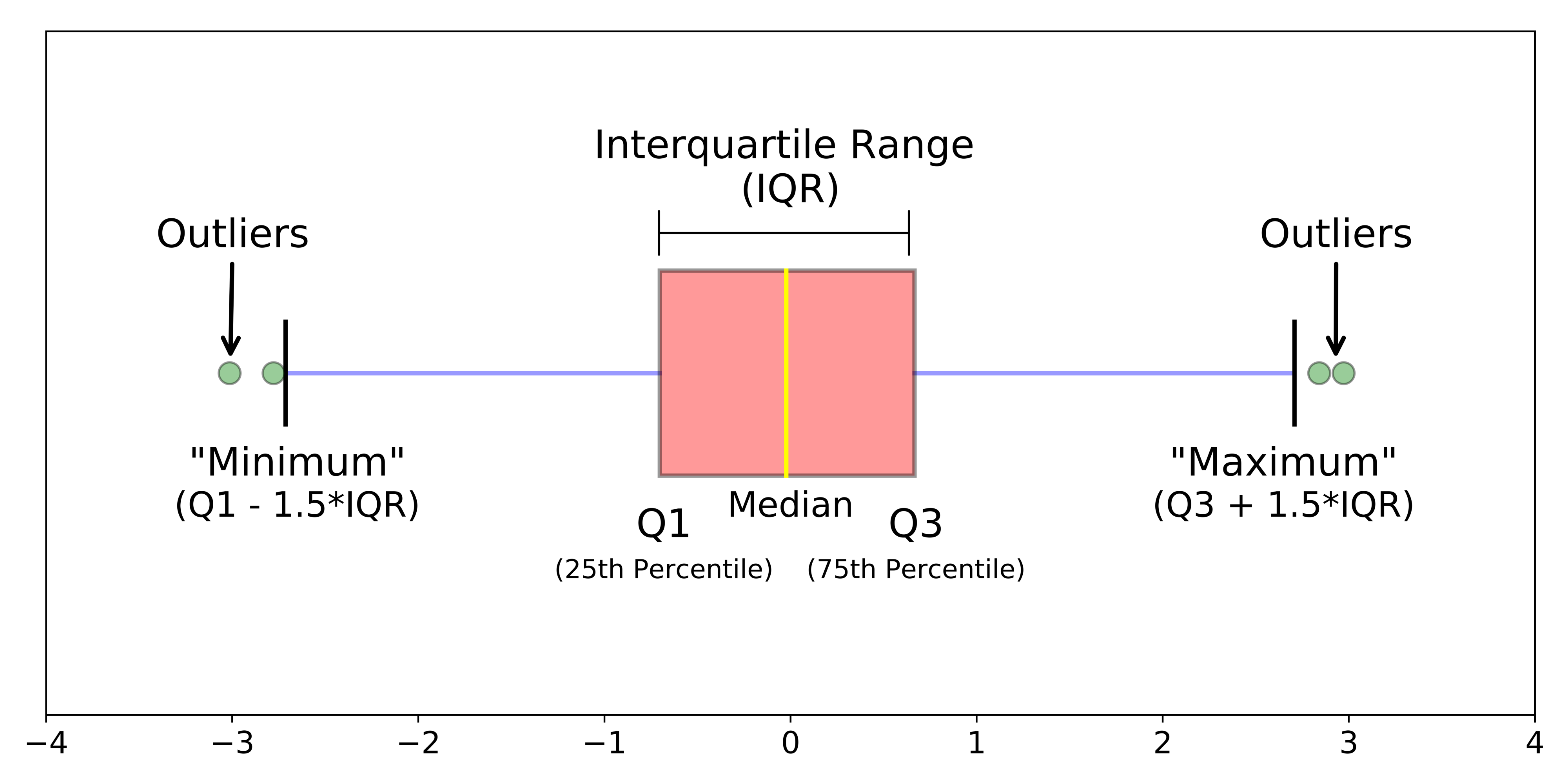
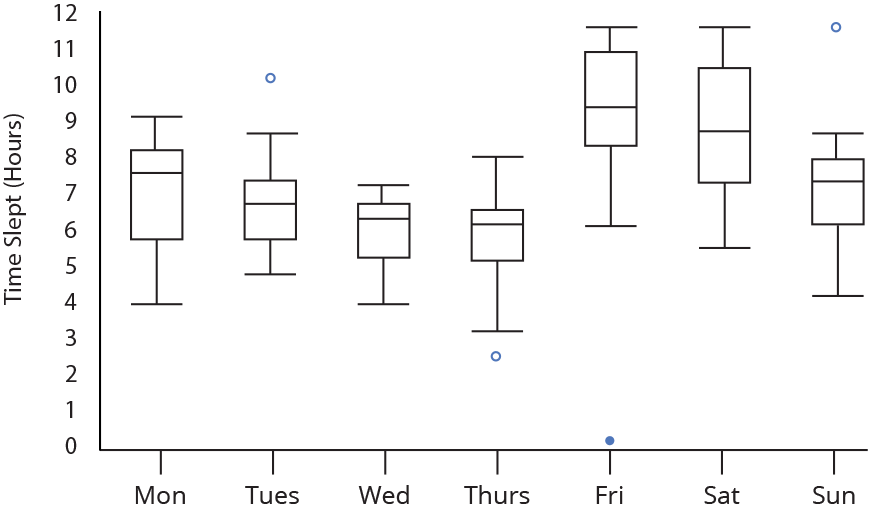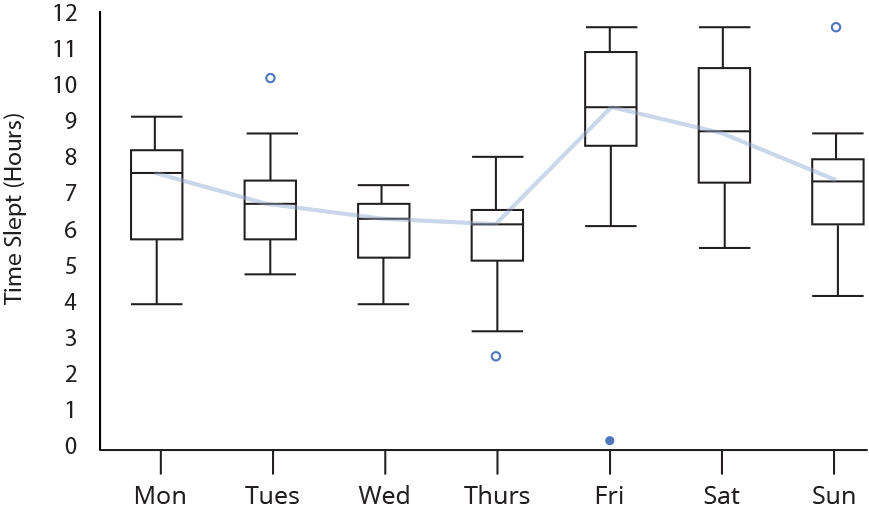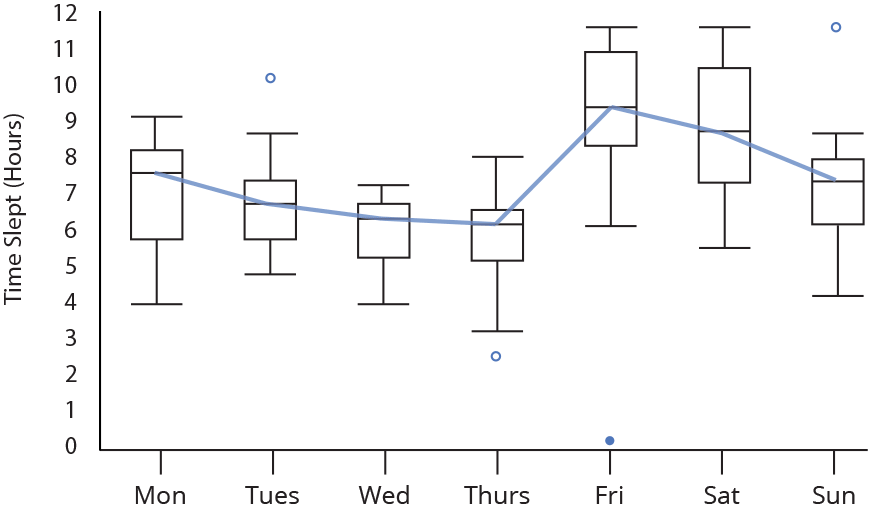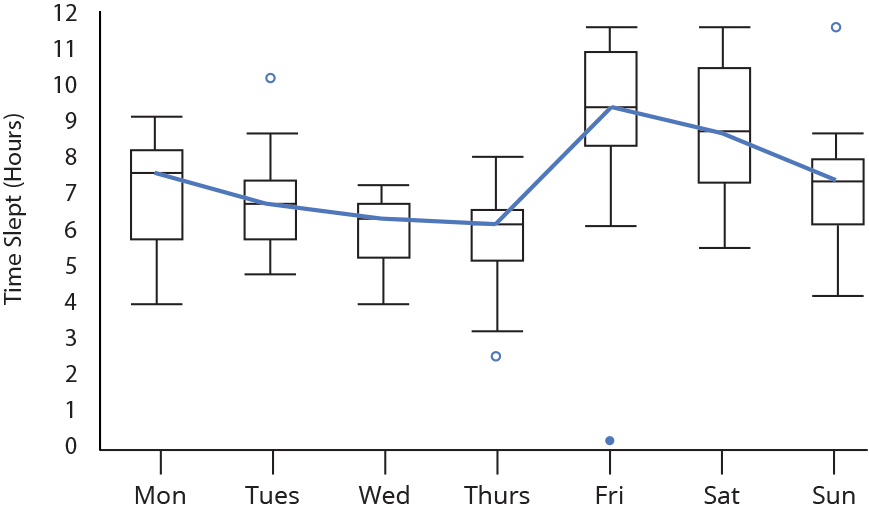
Gráfico de caixas (Box plot)
Representa dados de duas colunas
Dados do tipo categóricos: X = categórico e Y = contínuo
Resume informações de medidas contínuas para dois ou mais fatores categóricos
Gráfico de caixas (Box plot)
Intervalo inter-quartil (interquartile range - IQR)
Limite inferior e limite superipor (1.5 x IQR)
Valores exteriores (outliers)
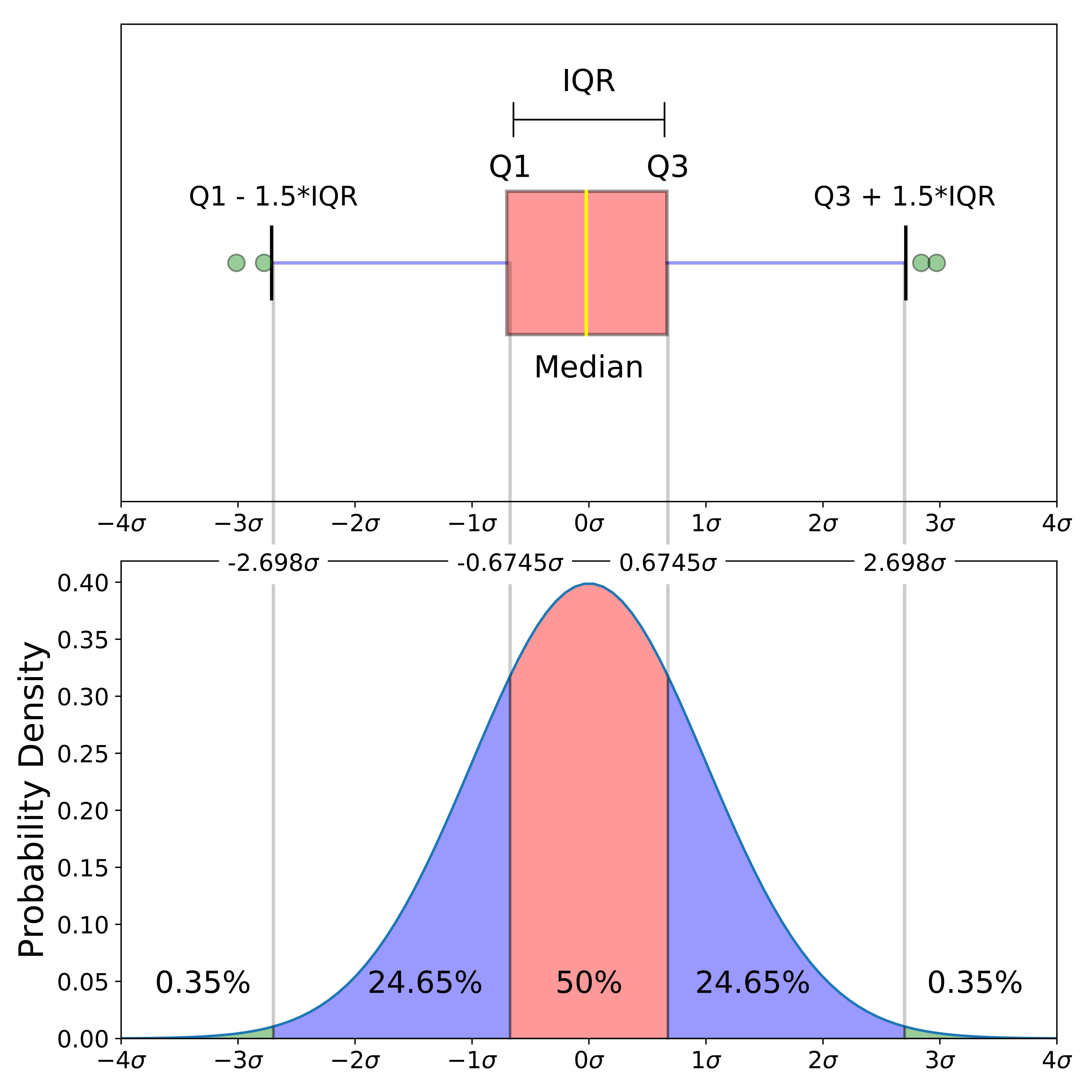
Outlier
Observação coletado de forma errônea ou devido à arredondamentos

Gráfico de caixas (Box plot)
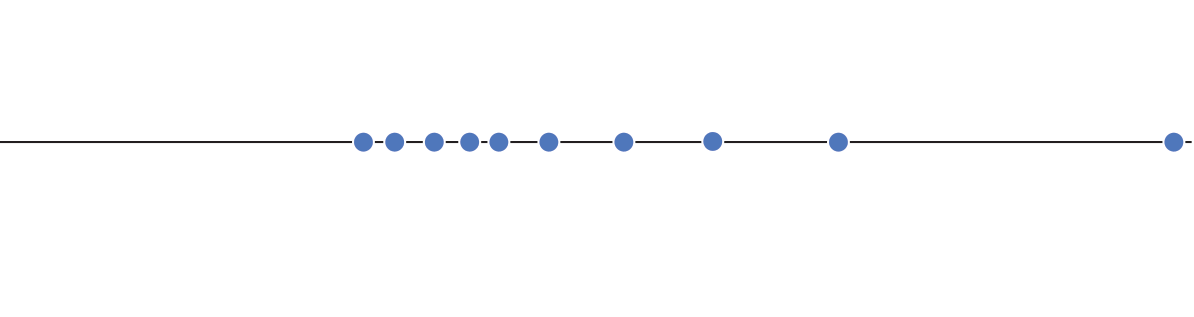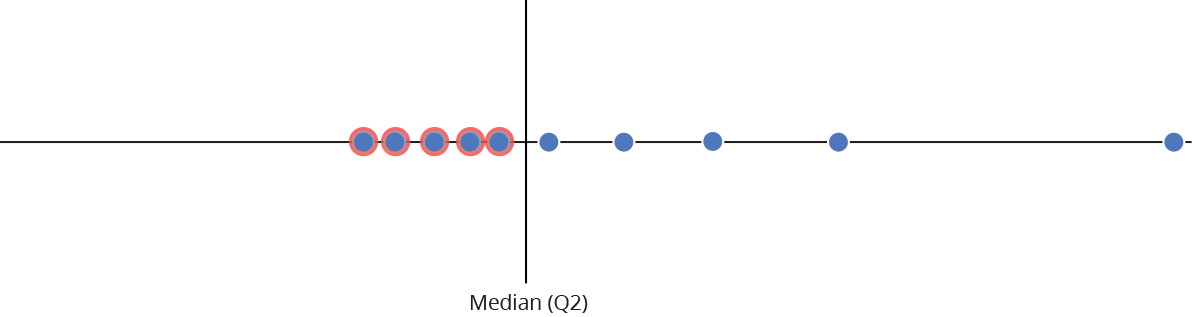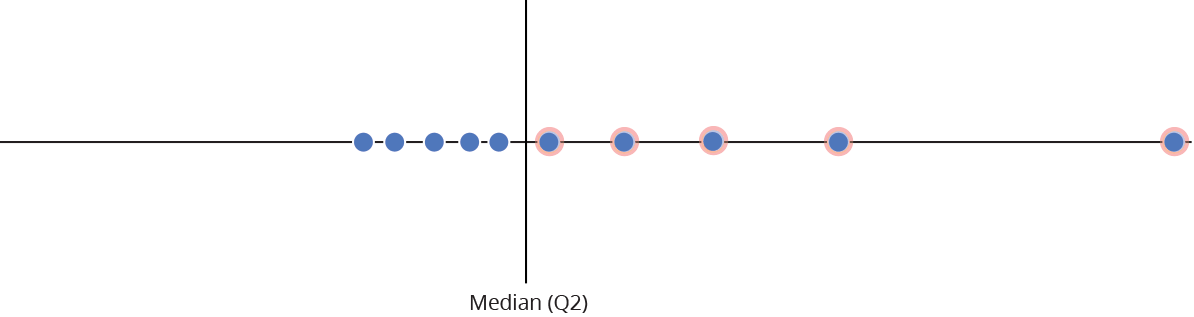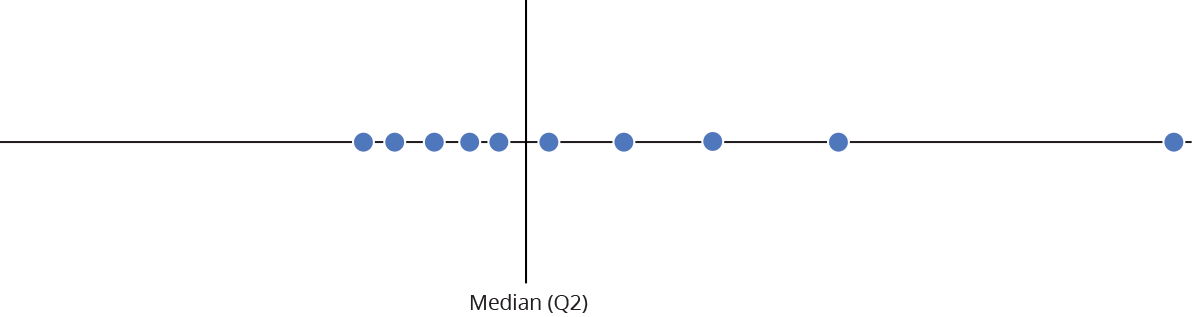
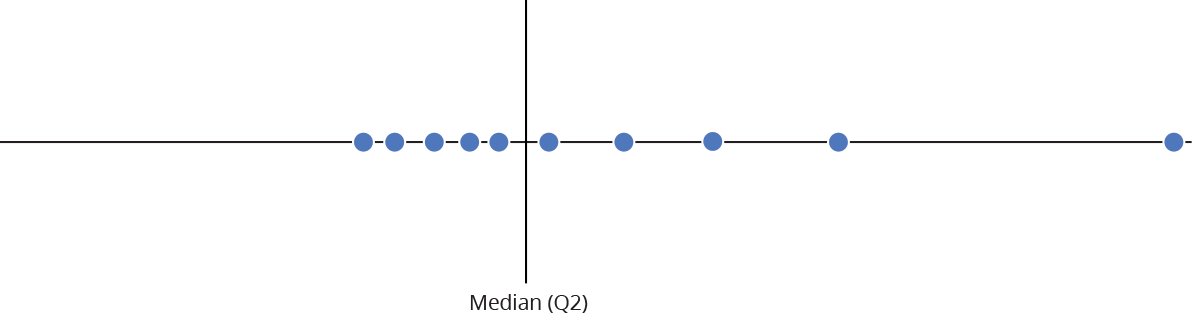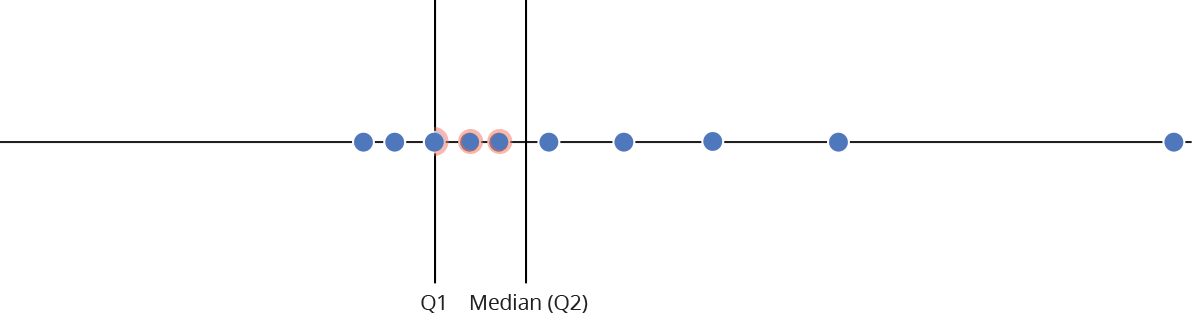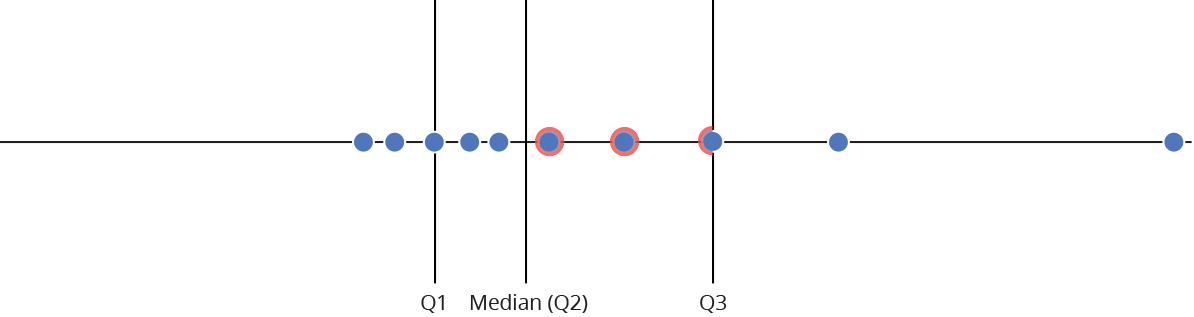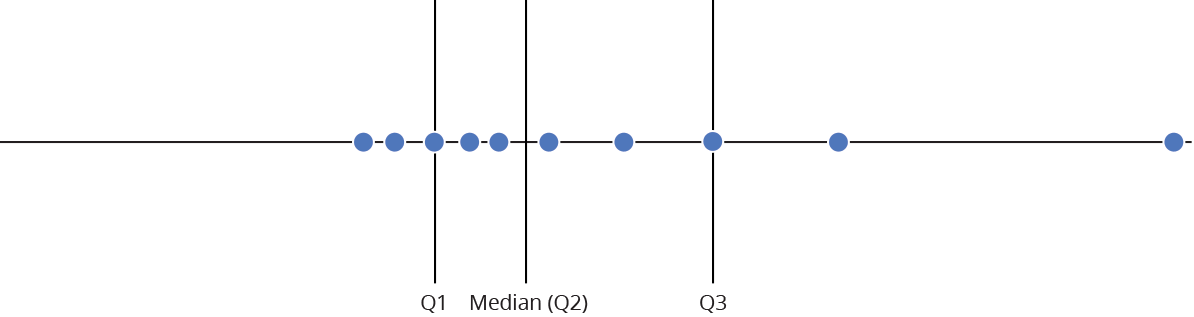
Gráfico de caixas (Box plot)
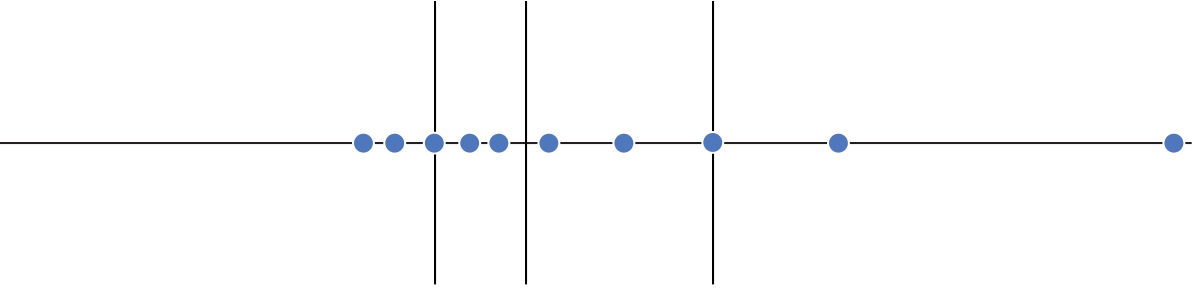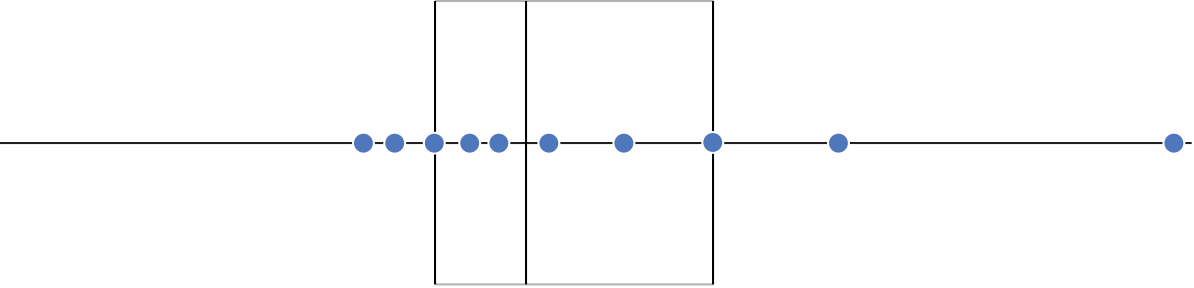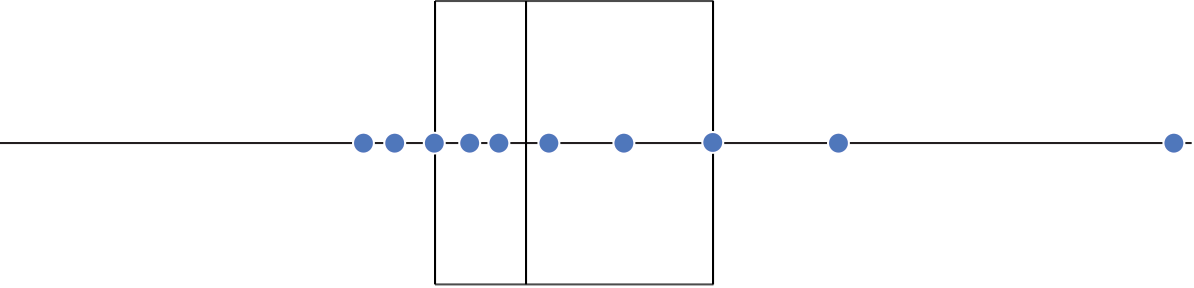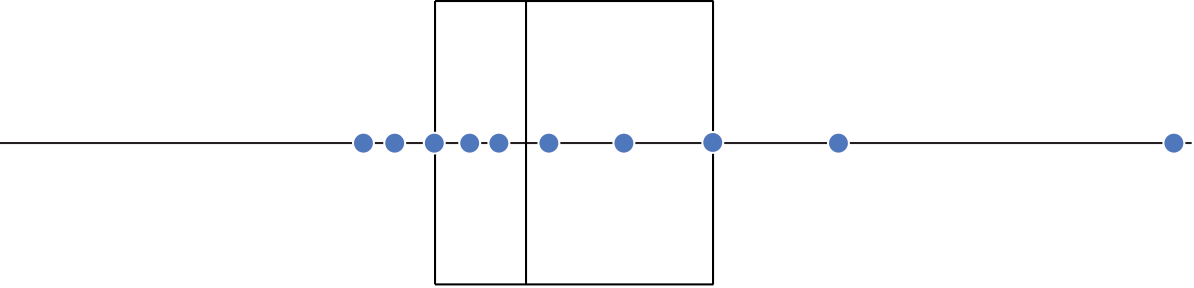
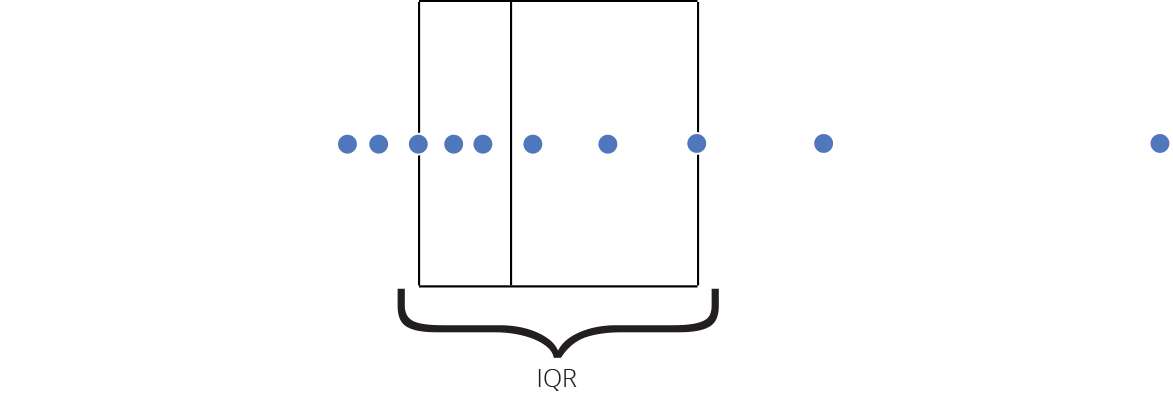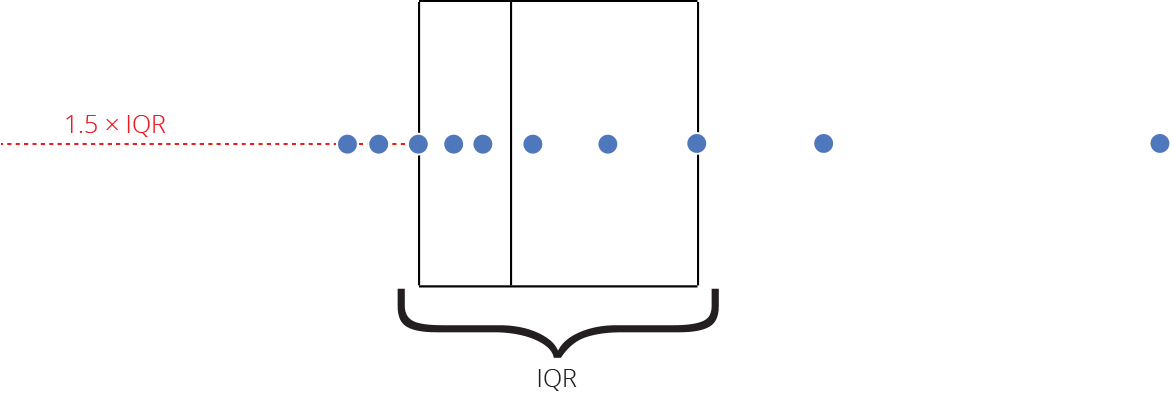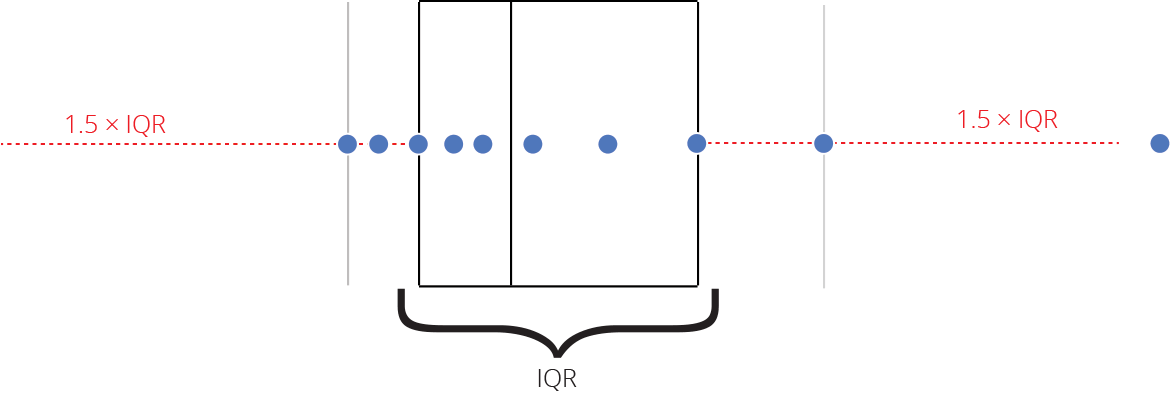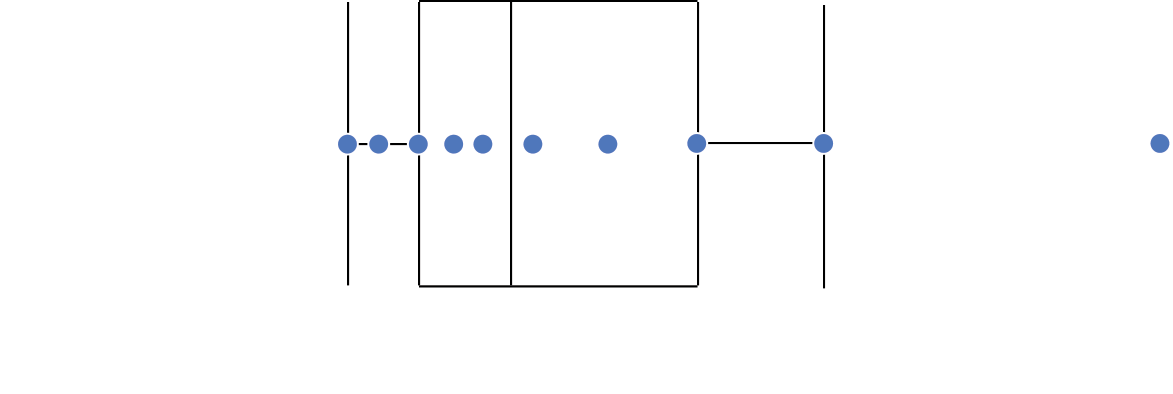
Gráfico de caixas (Box plot)
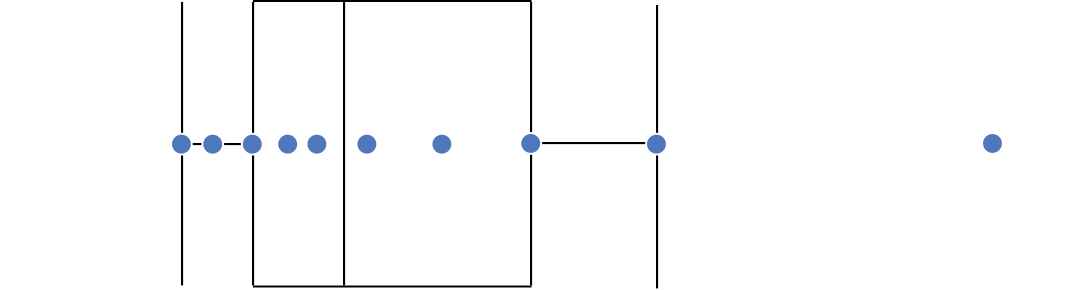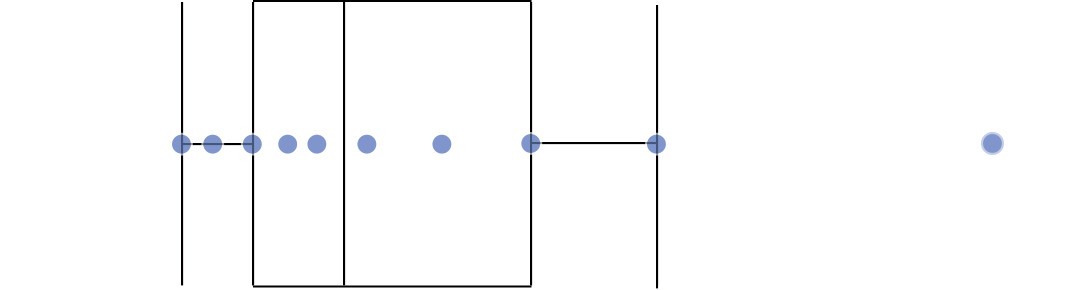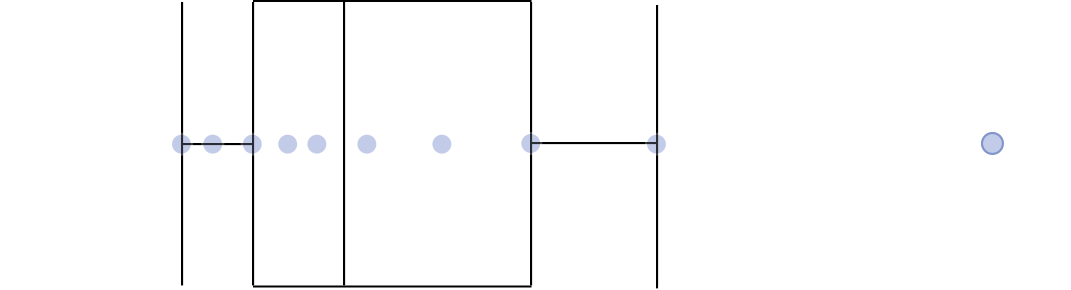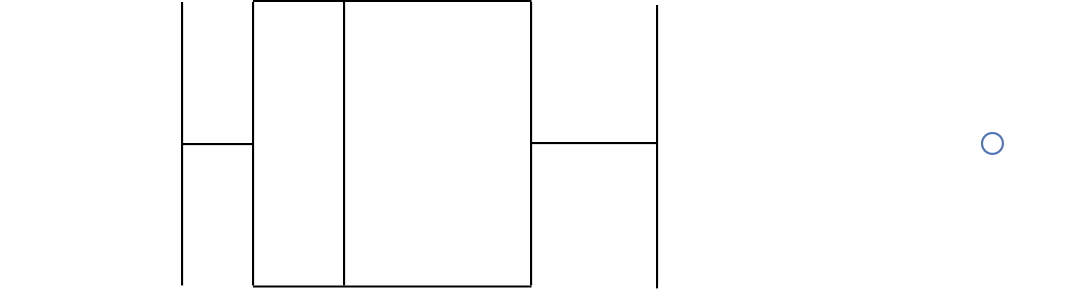
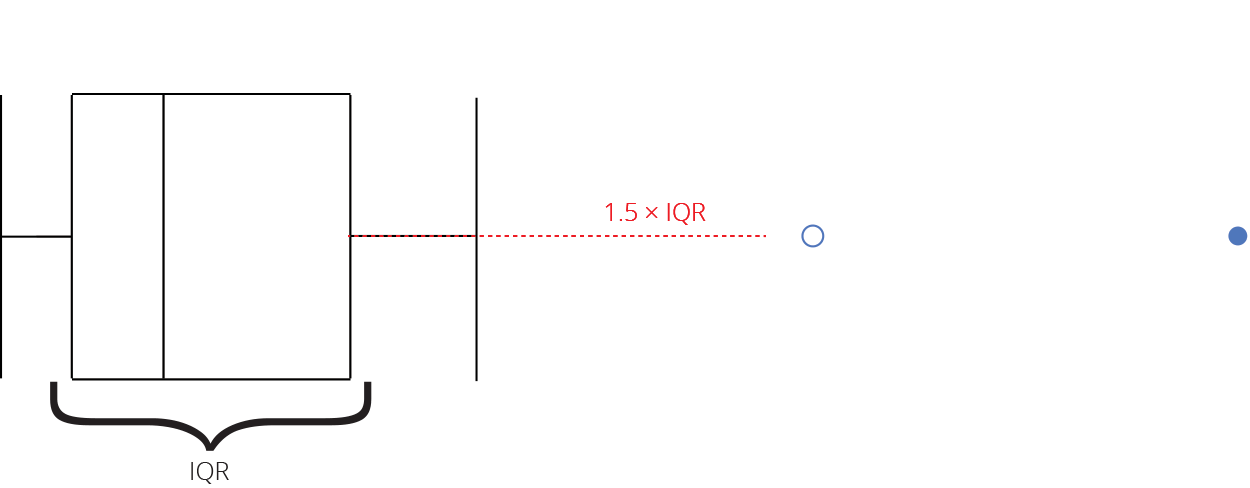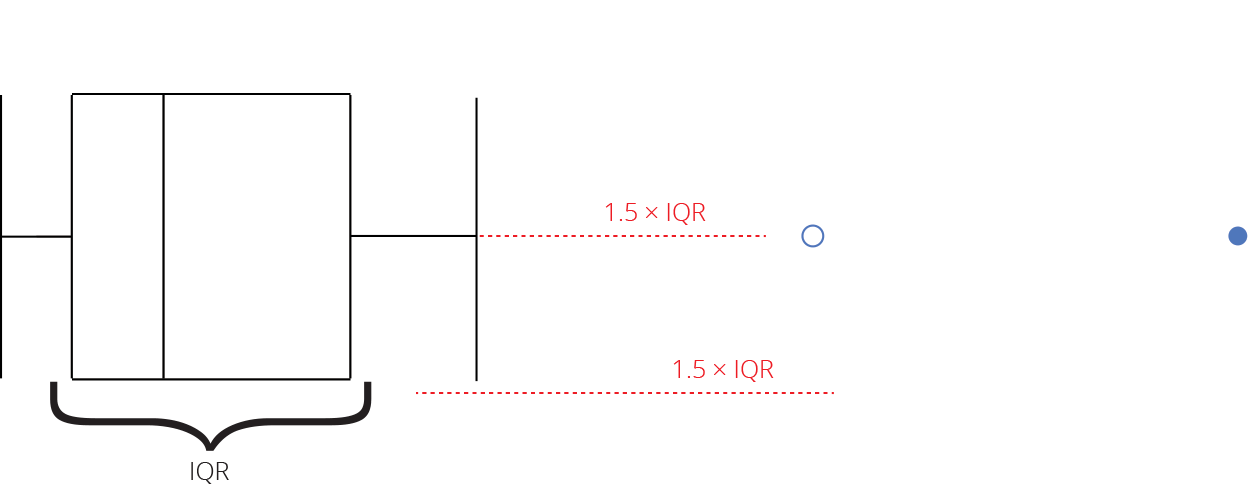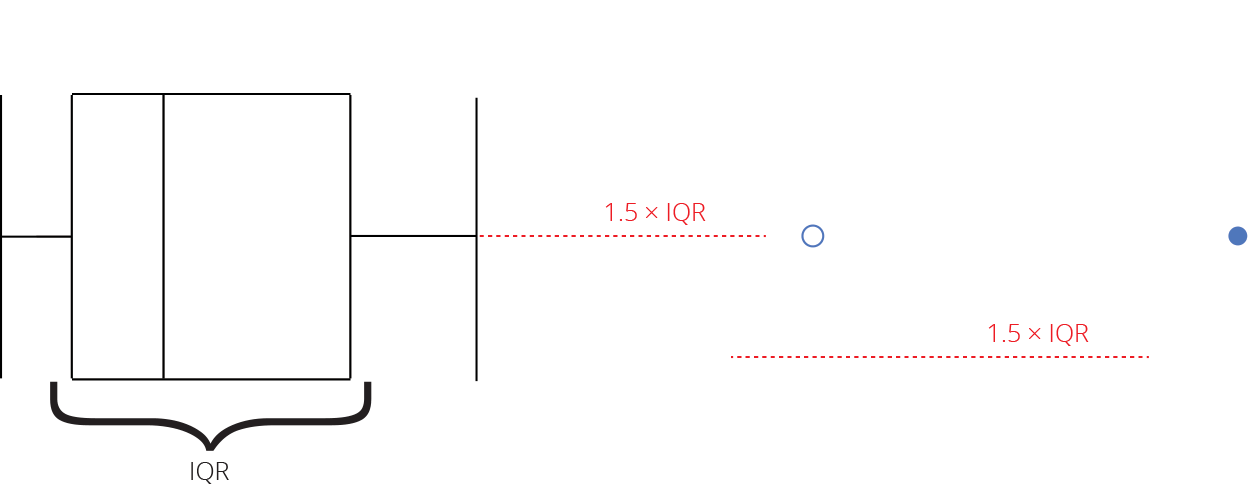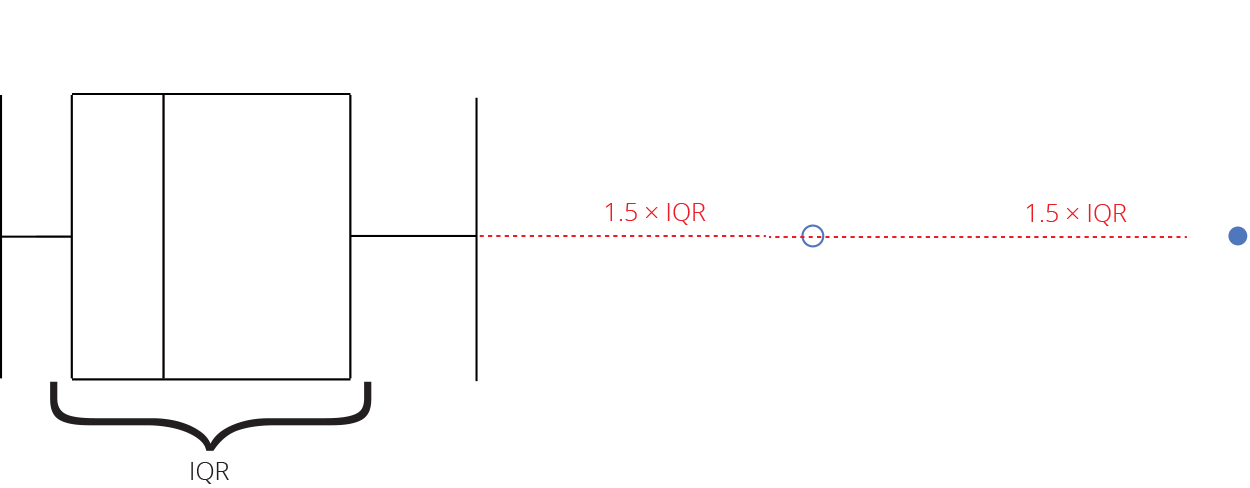
Gráfico de caixas (Box plot)
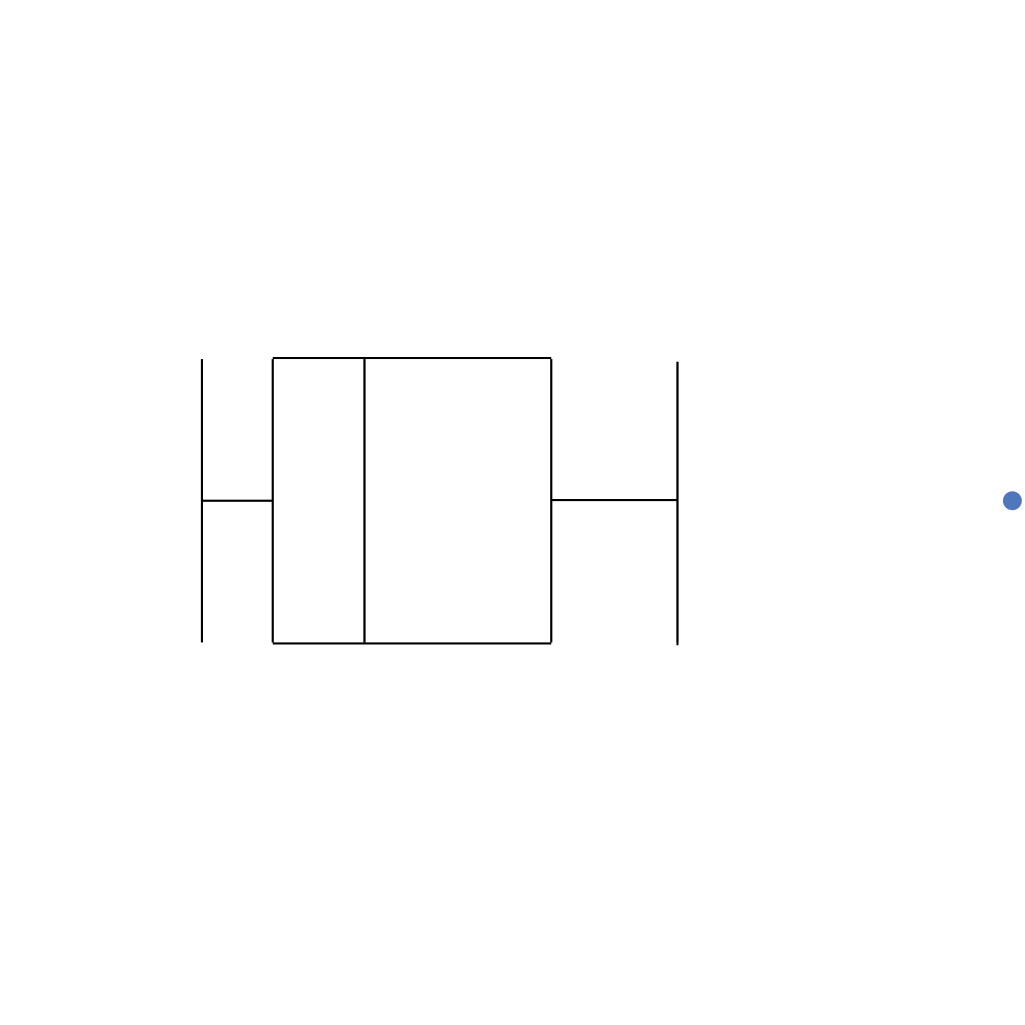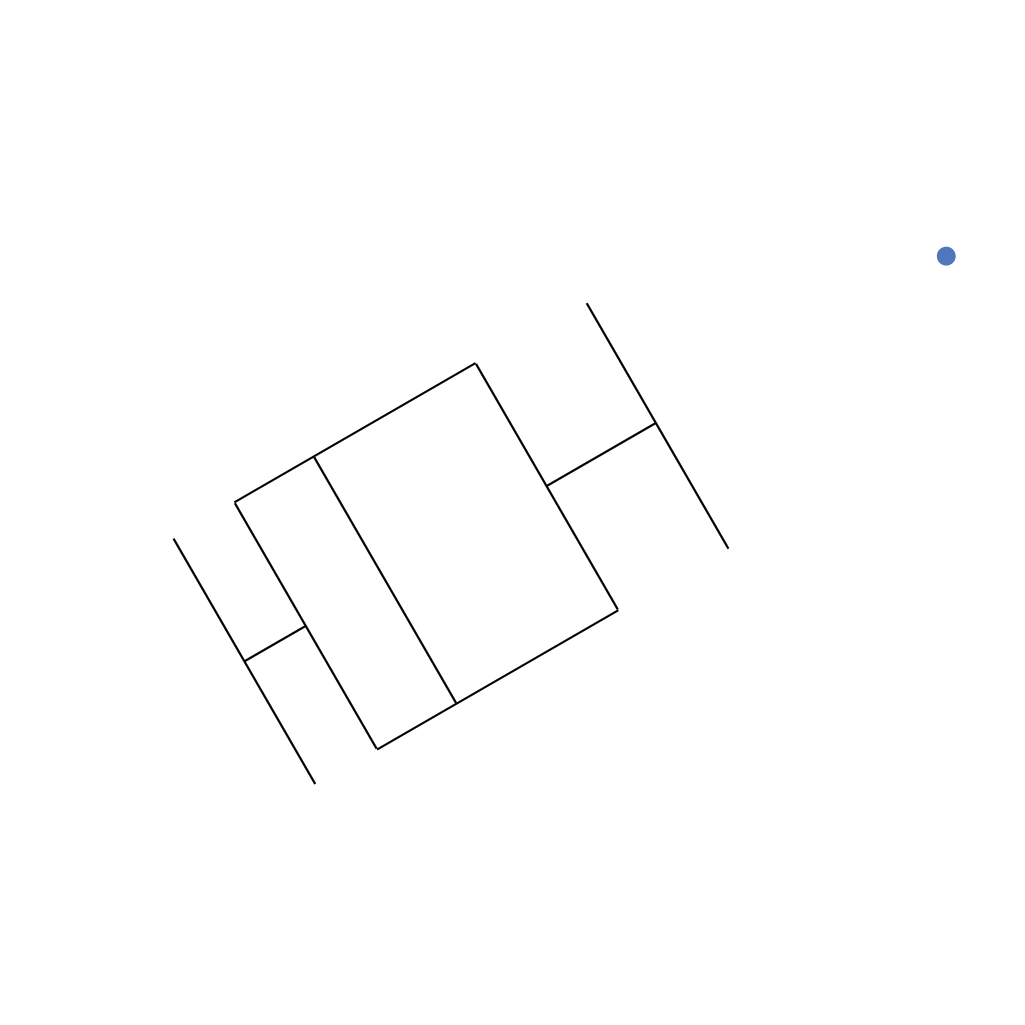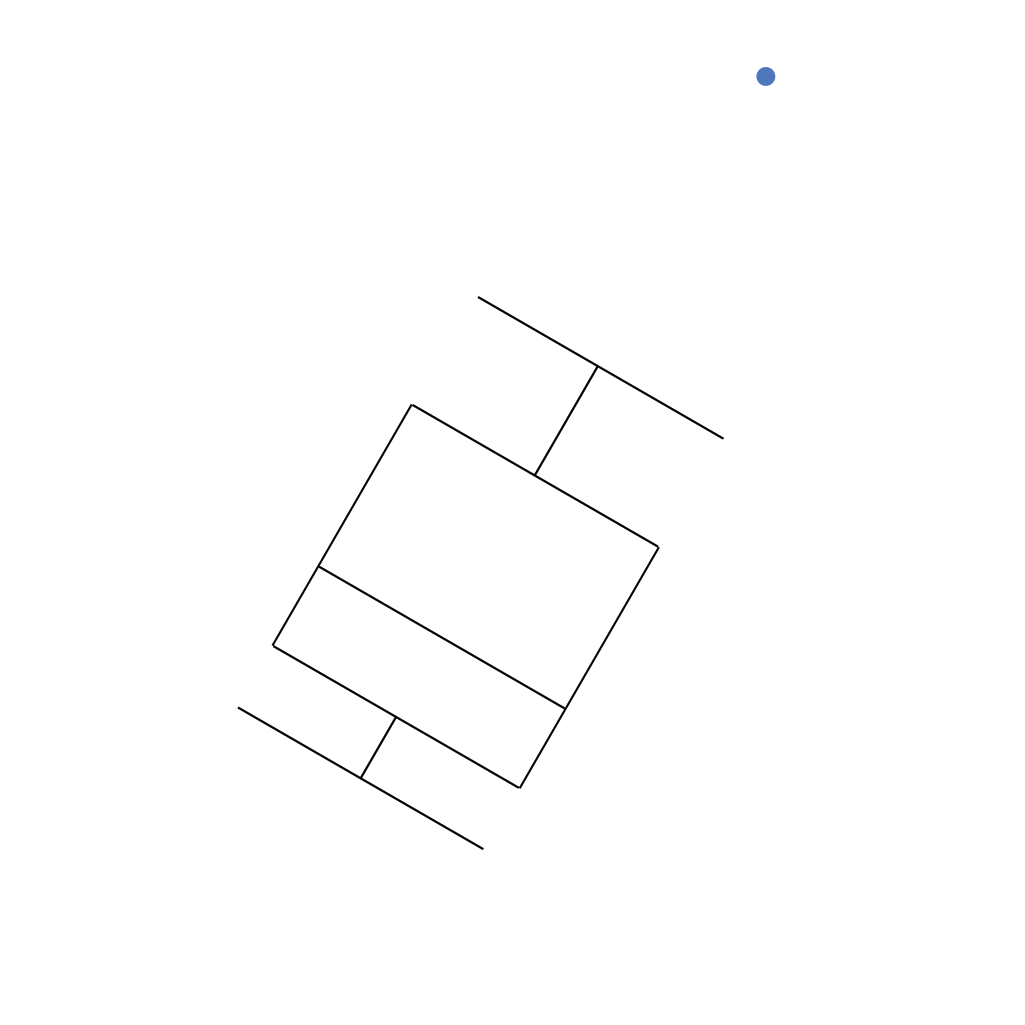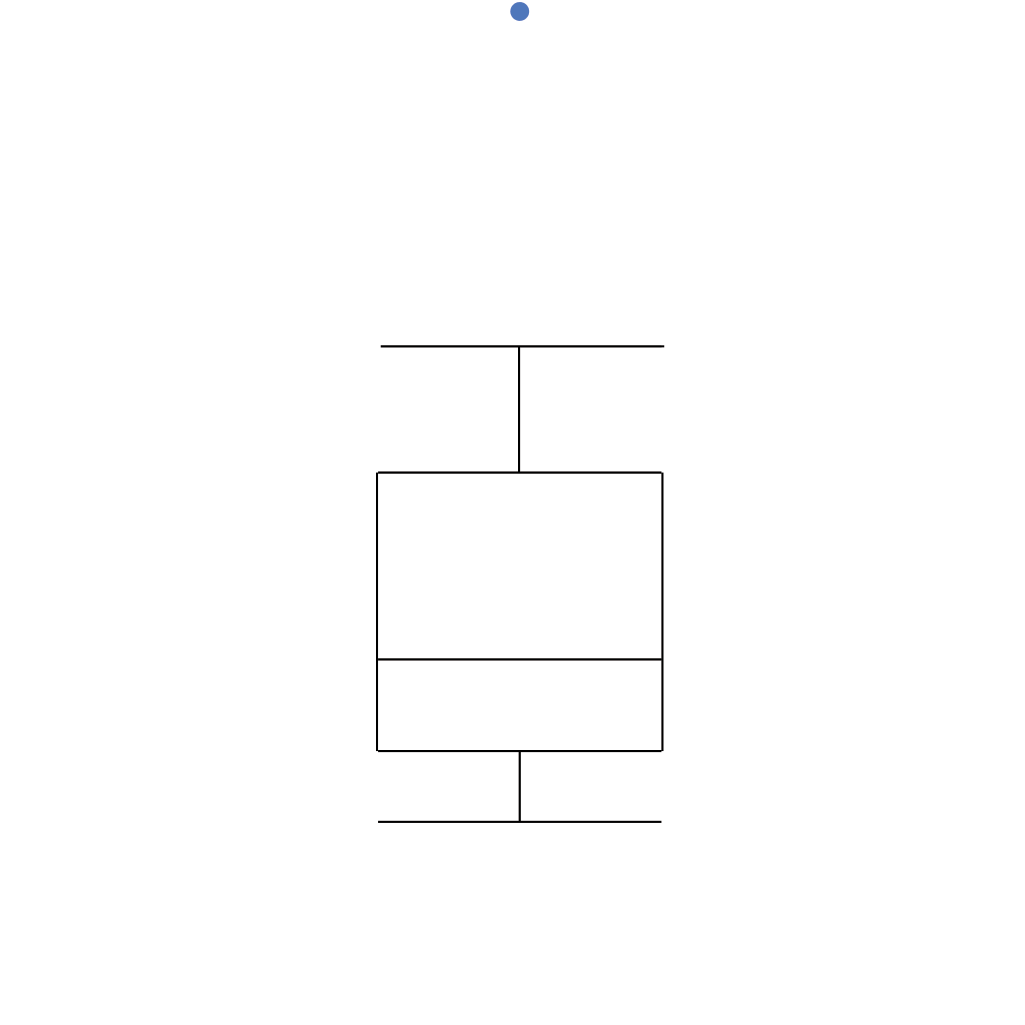
Gráfico de caixas (Box plot)
Pergunta e hipótese
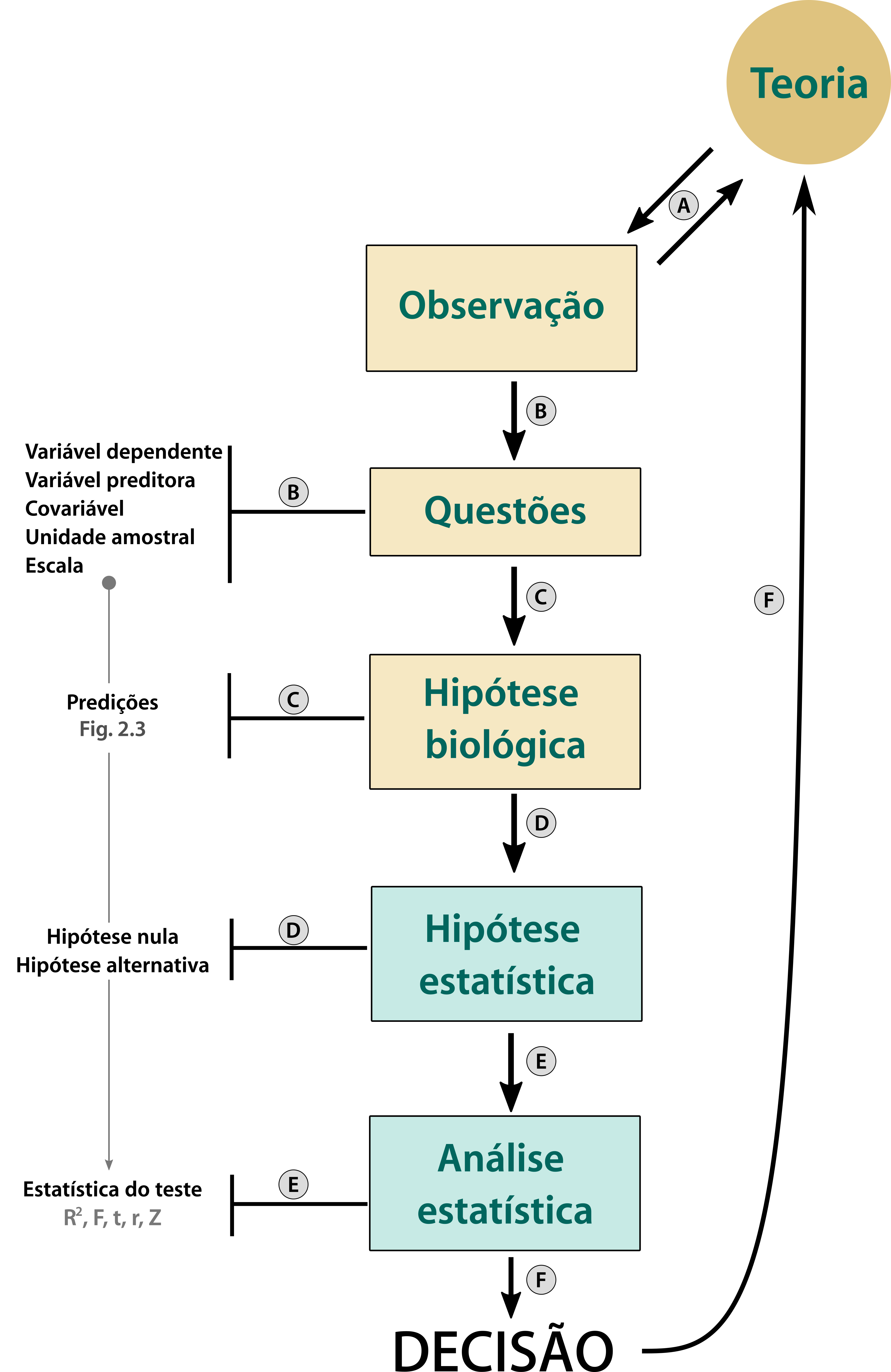
Método hipotético-dedutivo
A. Teoria ecológica/biológica
B. Desenho amostral (variáveis, unidade amostral, esforço, escala - temporal e espacial)
C. Hipótese ecológica/biológica e predições
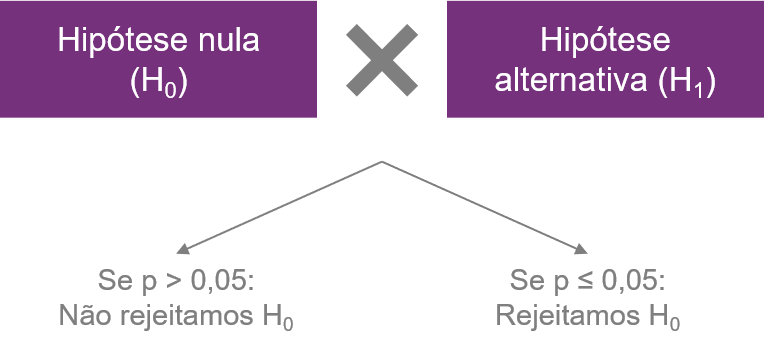
D. Hipótese estatística - hipótese nula (H0) e hipótese alternativa (H1)
E. Análise estatística - inferência (estatística ou estimador): p, R², F, t, z, r…
F. Decisão: interpretação à luz da teoria ecológica/biológica
Hipótese ecológica e estatística
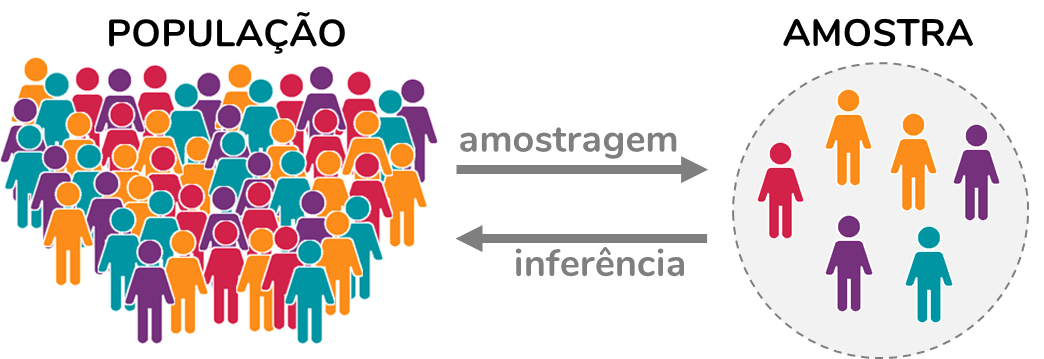
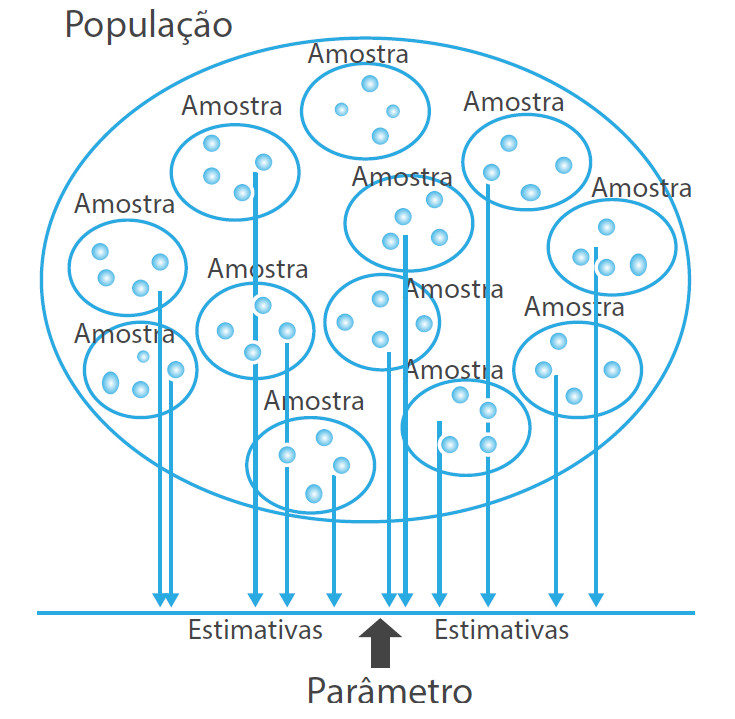
População e amostra
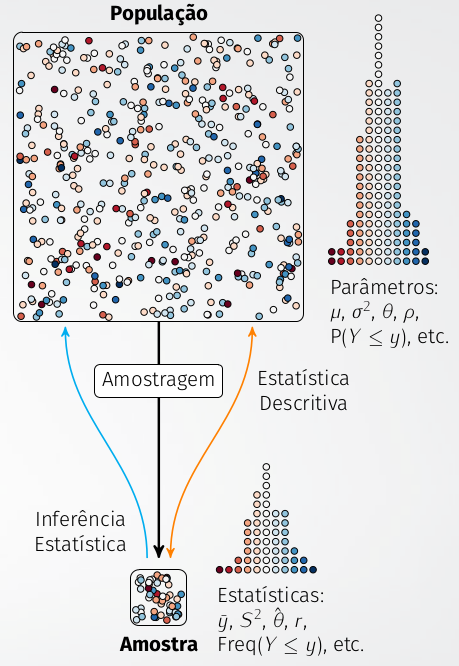
População: todos dados existentes
Amostra: parte dos dados coletados
Amostragem: processo de coleta de dados
Estatística descritiva: análise descritiva dos dados coletados (medidas-resumo, tabela e gráficos)
Inferência estatística: análise inferencial da amostra para afirmar algo sobre a população (testes estatísticos)
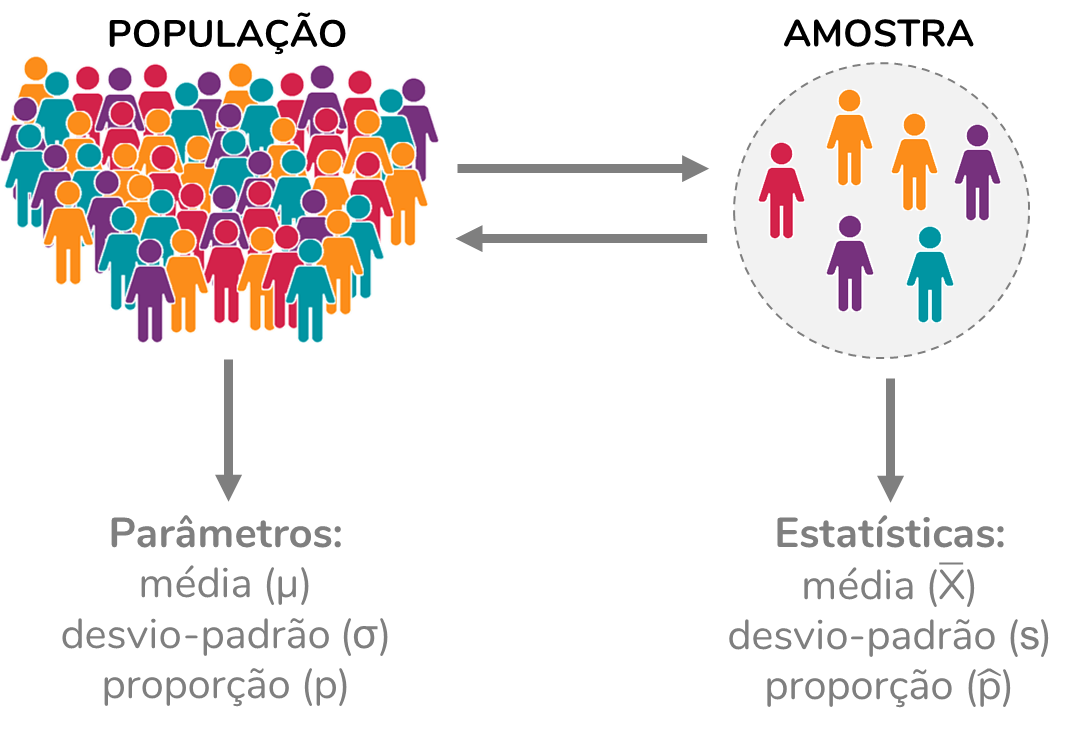
Parâmetros: medidas sobre a população (média, variância, desvio padrão) (letras gregas)
Estatísticas (estimadores): medidas sobre a amostra (média, variância, desvio padrão, erro padrão) (letras romanas)
Parâmetro e estatística (estimador)
Média
Média da população (parâmetro)
\[\mu=\sum \frac{x_{i}}{n}\]
Média da amostra (estatística)
\[\bar{x}=\sum \frac{x_{i}}{n}\]
Variância
Variância da população (parâmetro)
\[\sigma^2=\sum \frac{(x_{i}-\bar{x})^2}{n}\]
Variância da amostra (estatística)
\[s^2=\sum \frac{(x_{i}-\bar{x})^2}{n}\]
Desvio padrão
Desvio padrão da população (parâmetro)
\[\sigma =\sqrt {\sum \frac{(x_{i}-\bar{x})^2}{n}}\]
Desvio padrão da amostra (estatística)
\[s =\sqrt {\sum \frac{(x_{i}-\bar{x})^2}{n}}\]
Erro padrão
Erro padrão da média amostral
Variação da média amostral em relação à média populacional (confiabilidade da média amostral)
\[s_\bar{x} =\frac{s}{\sqrt{n}}\]
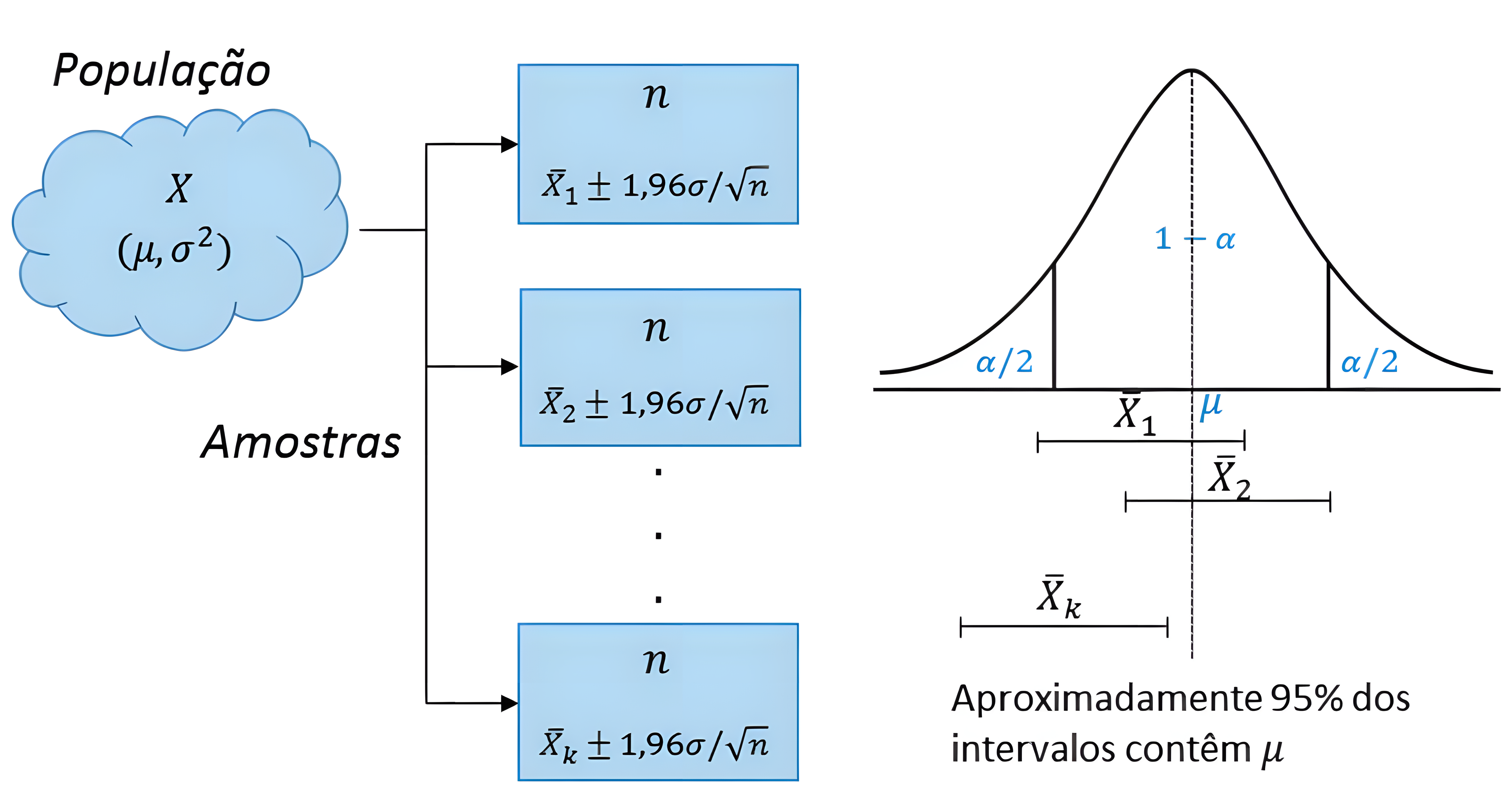
Inferência estatística
Conclusões sobre características da população (parâmetros) através de estatísticas (estimadores) calculadas a partir da(s) amostra(s)

Inferência estatística
Duas categorias:
- Estimação pontual com um intervo (intervalo de confiança)
- Testes de hipóteses (testar afirmações)
Distribuição z
Distribuição de probabilidades de z, com média de z (μ = 0) e desvio padrão de z (σ² = 1)
Como estimamos valores acima e abaixo da média populacional, e para um nível de significância de 5% (α = 0.05), dividimos (α/2 = 0.025) e (1 - α/2 = 0.975)

Distribuição t
Graus de liberdade (g.l.): quantidade de observações (n) menos a quantidade de parâmetros estimados (μ)
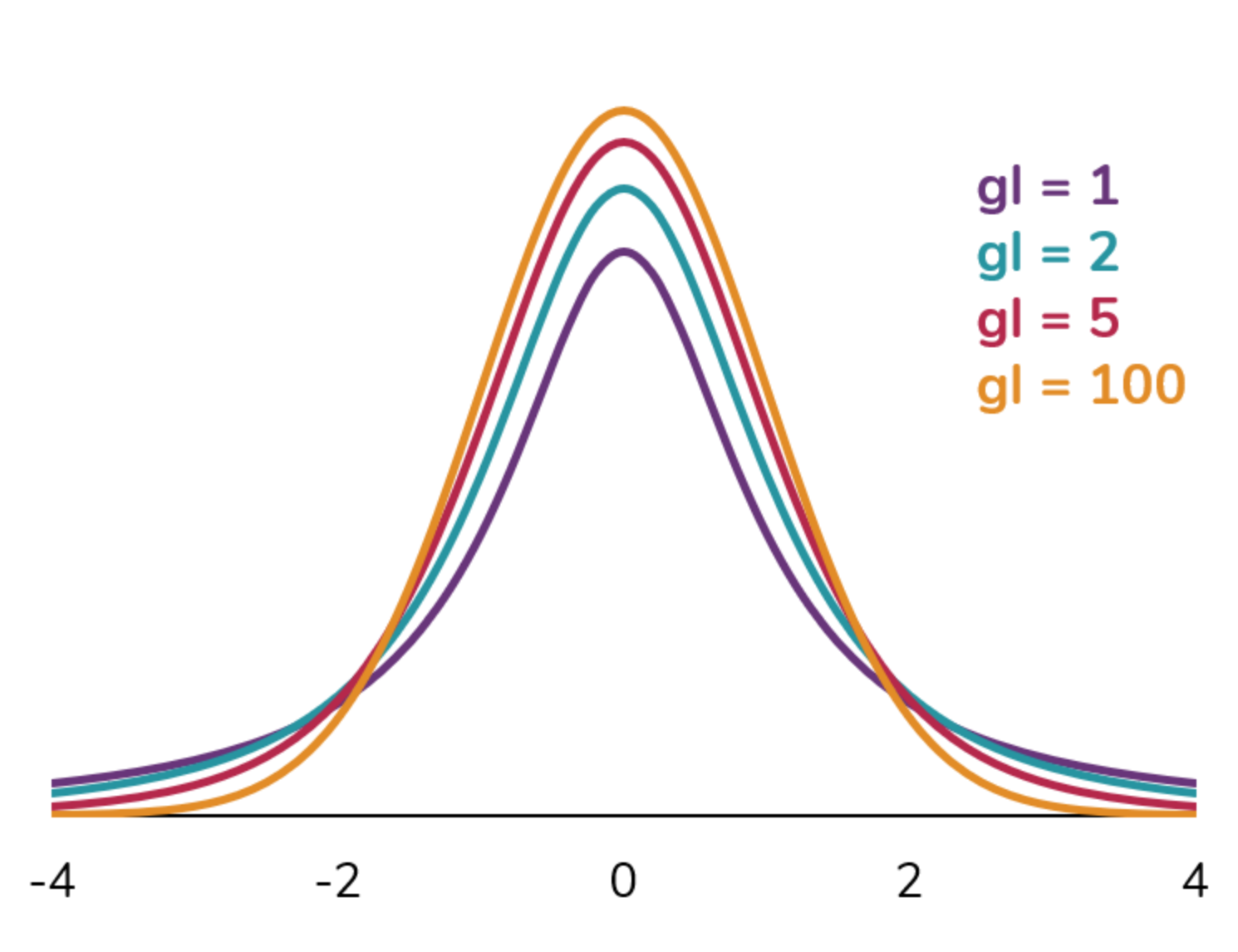
Teste de hipóteses
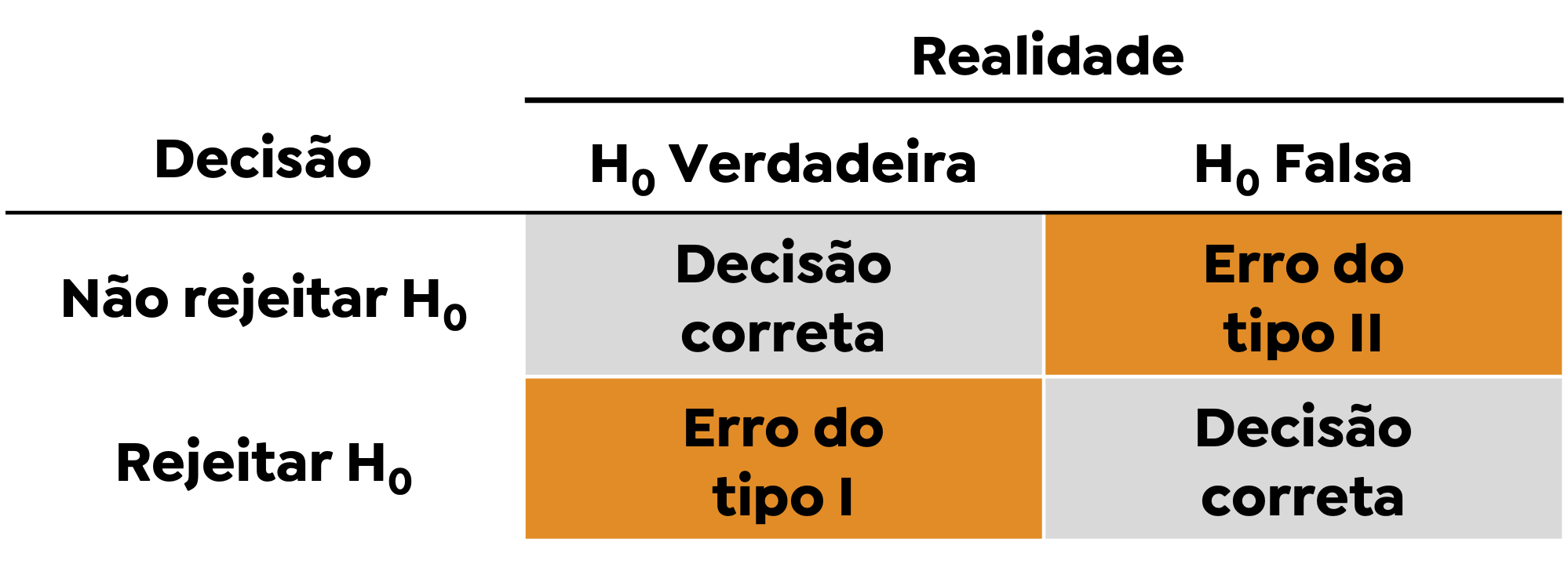
Erros
- Erro do tipo I: rejeitar H0 quando H0 é verdadeira
α = P(erro do tipo I) = P(rejeitar H0|H0 é verdadeira)
- Erro do tipo II: não rejeitarmos H0 quando H0 é falsa
β = P(erro do tipo II) = P(não rejeitar H0|H0 é falsa)
Teste de hipóteses
Detalhamento
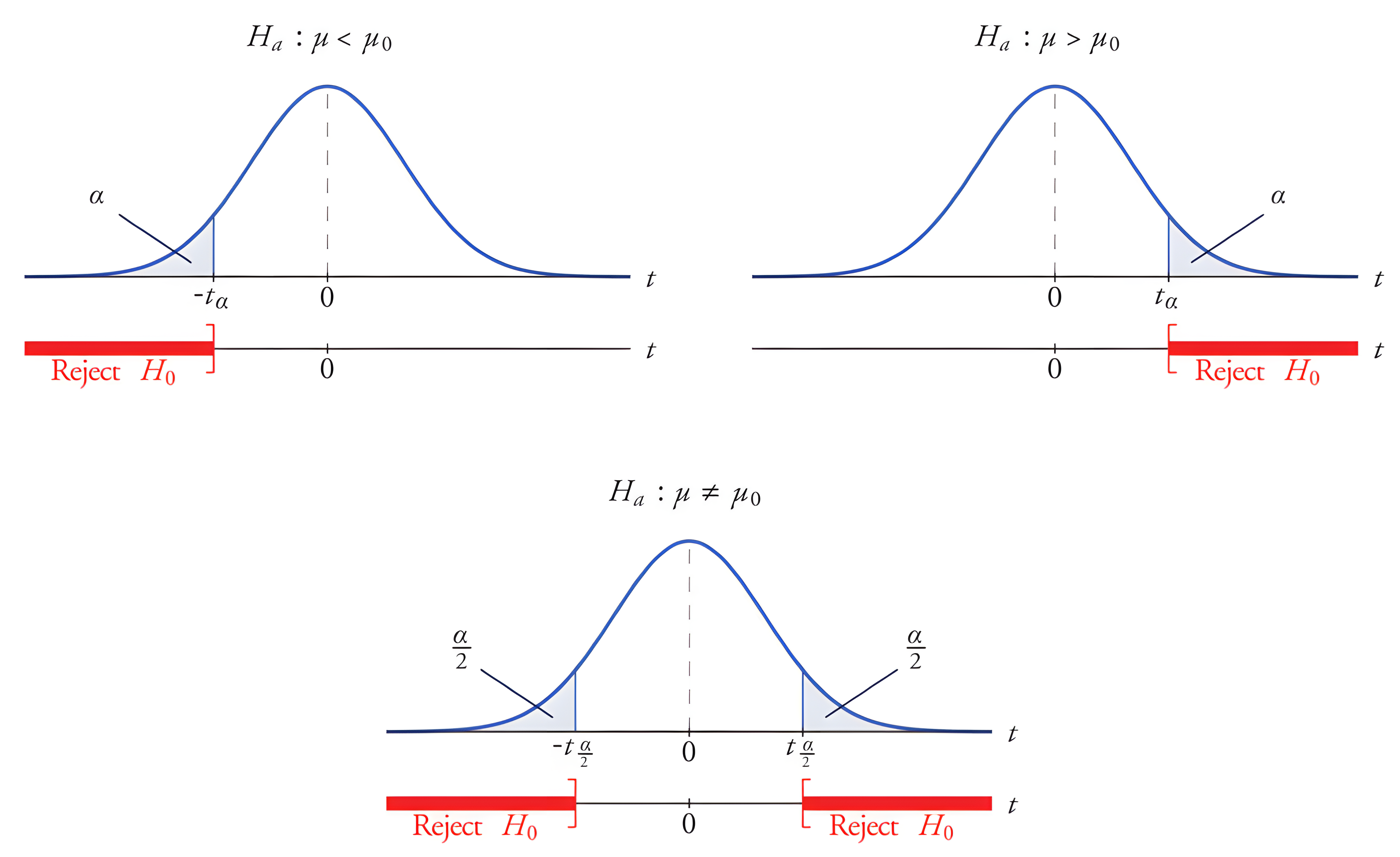
4 Definir a região crítica (RC)
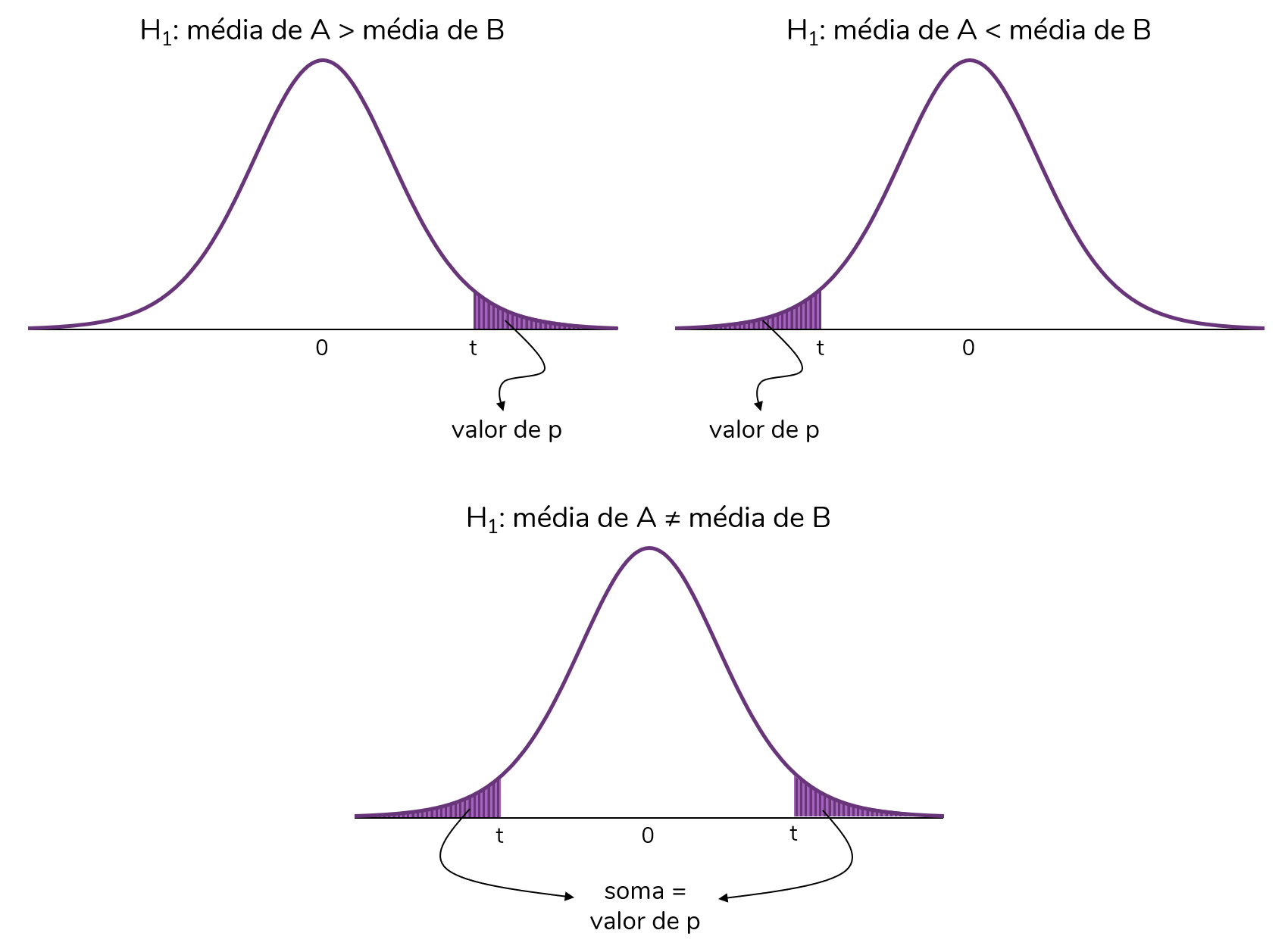
H0: µ = µ0
H1: µ ≠ µ0
H0: µ = µ0
H1: µ < µ0
H0: µ = µ0
H1: µ > µ0
Teste de hipóteses
Exemplo
- A região crítica é do tipo (teste unicaldal à direita)
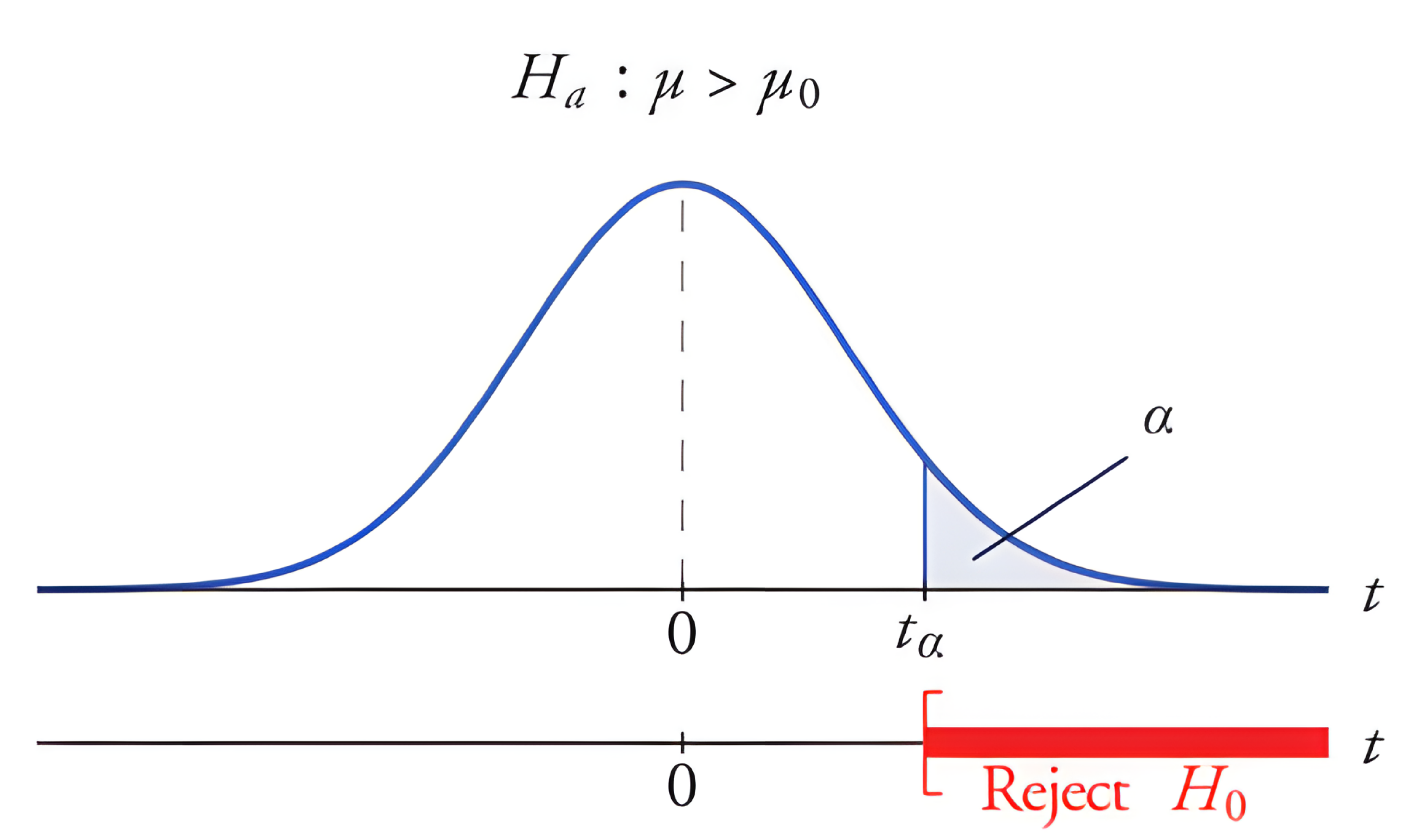
onde t = t(n-1, α) = t(24,0.05) = 1.71 (tabela da distribuição t)
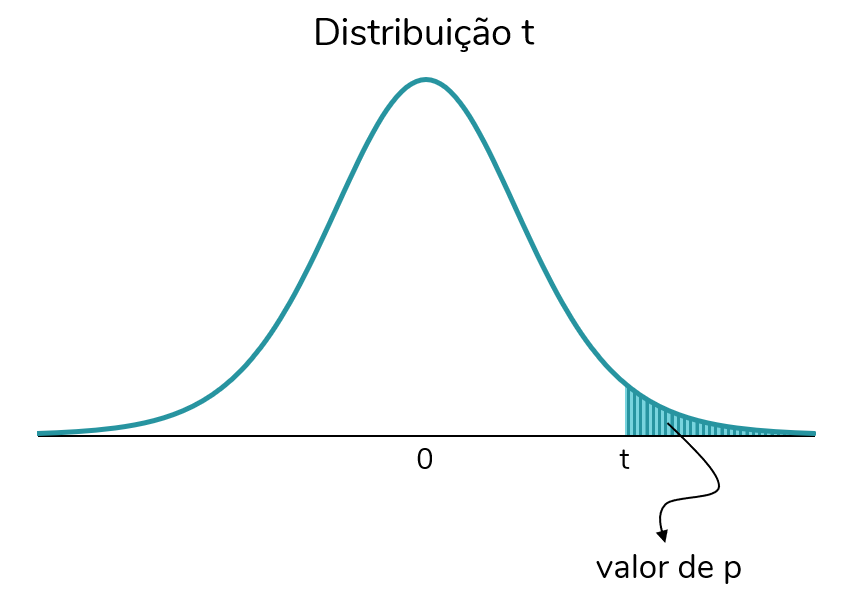
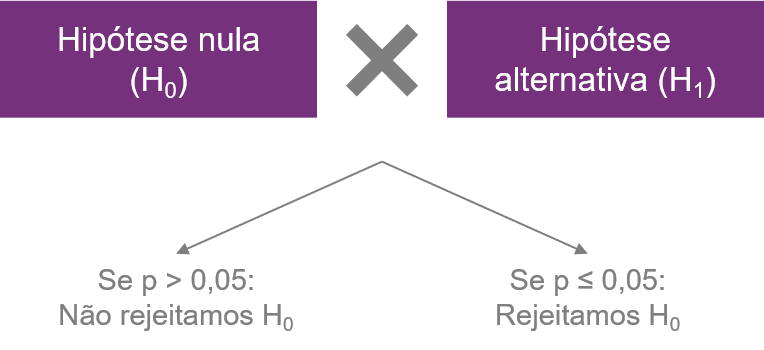
Valor de p
Probabilidade de termos obtido aqueles resultados (ou mais extremos), dado que a H0 é verdadeira
P(resultados | H0 é verdadeira)
Valor de p
Probabilidade de termos obtido aqueles resultados (ou mais extremos), dado que a H0 é verdadeira
P(resultados | H0 é verdadeira)
Teste t
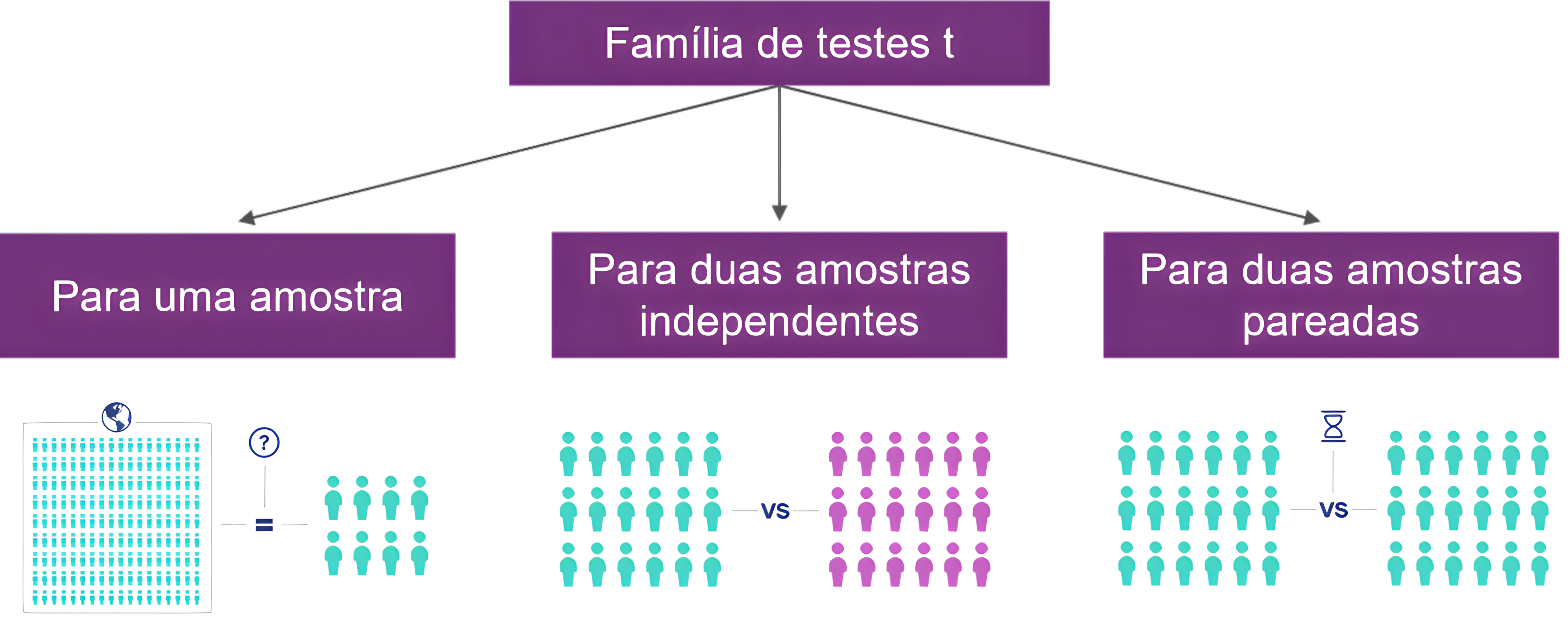
Teste t para uma amostra
One sample t test
Teste t
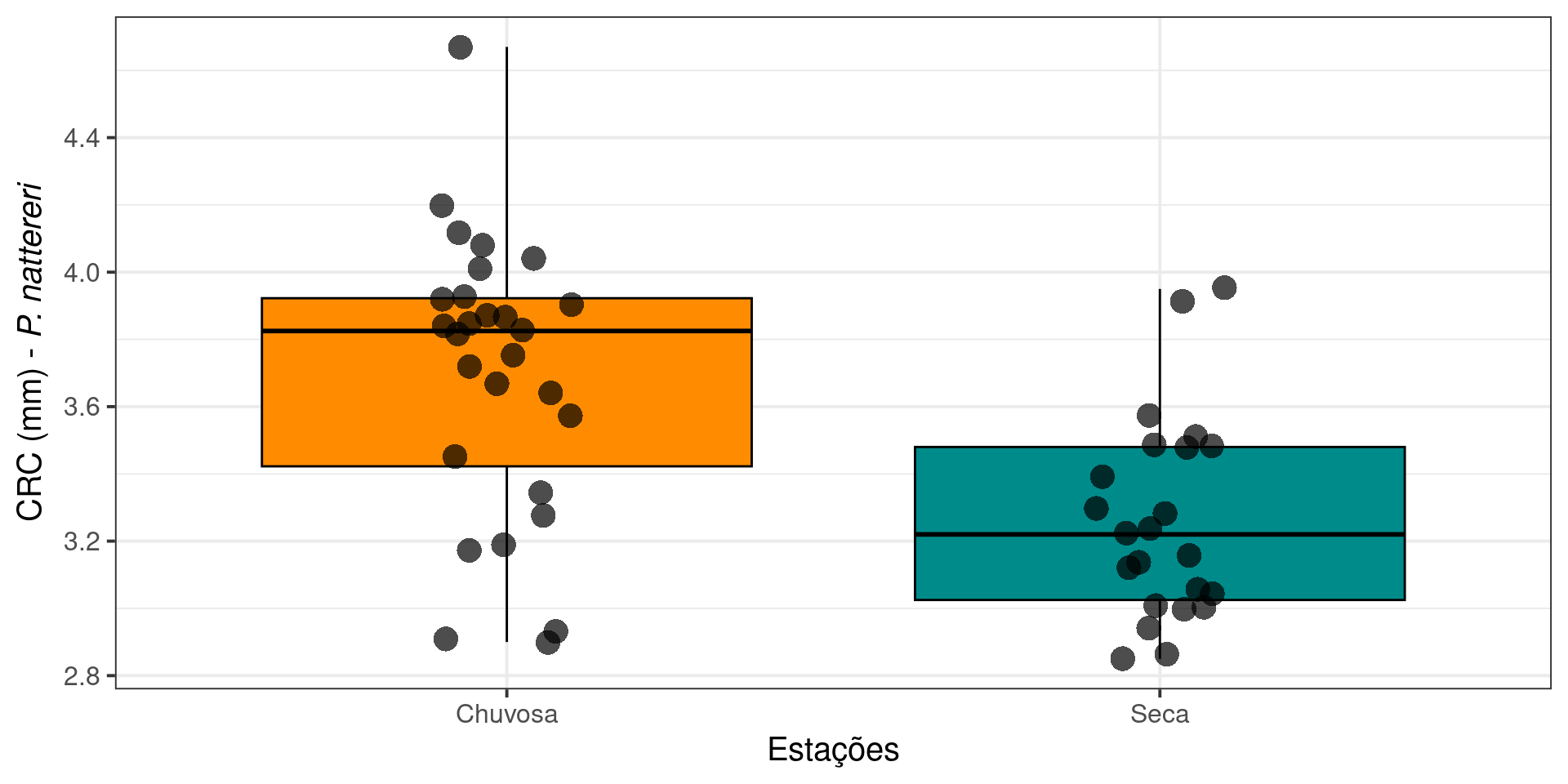
Physalaemus nattereri
Comprimento rostro-cloacal (CRC)

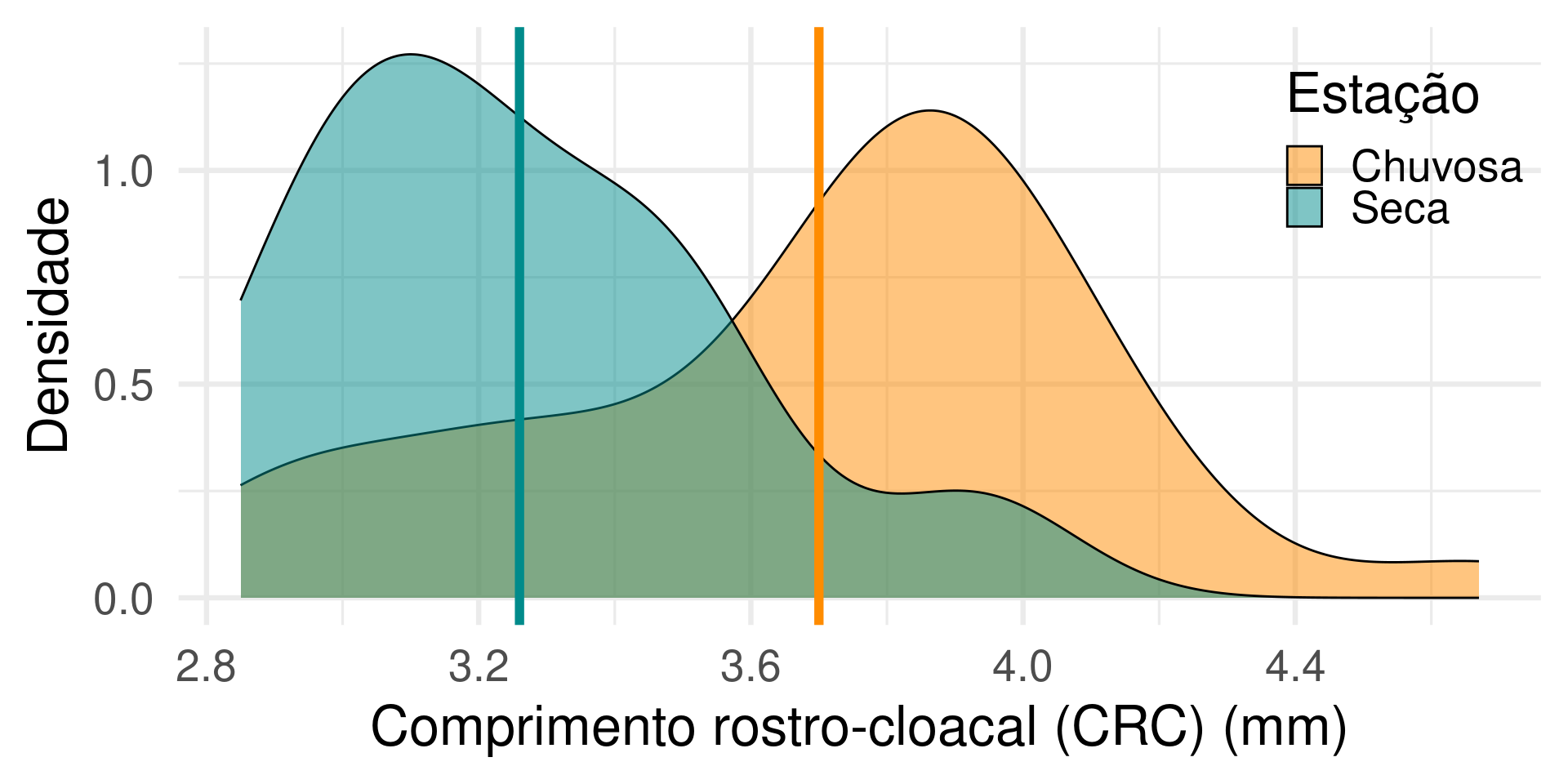
Teste t para duas amostras indep.
Independent-samples t test
| Estacao | mean | sd |
|---|---|---|
| Chuvosa | 3.70 | 0.42 |
| Seca | 3.26 | 0.30 |
Teste t para duas amostras indep.
Independent-samples t test
## Teste de normalidade dos residuos - H0: distribuicao dos residuos é normal
residuos <- residuals(lm(CRC ~ Estacao, data = teste_t_var_igual))
shapiro.test(residuos)
Shapiro-Wilk normality test
data: residuos
W = 0.98307, p-value = 0.6746
Teste t para duas amostras indep.
Independent-samples t test
## Teste de homogeneidade de variancia - H0: variancia e homogenea
car::leveneTest(CRC ~ as.factor(Estacao), data = teste_t_var_igual)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 1.1677 0.2852
49 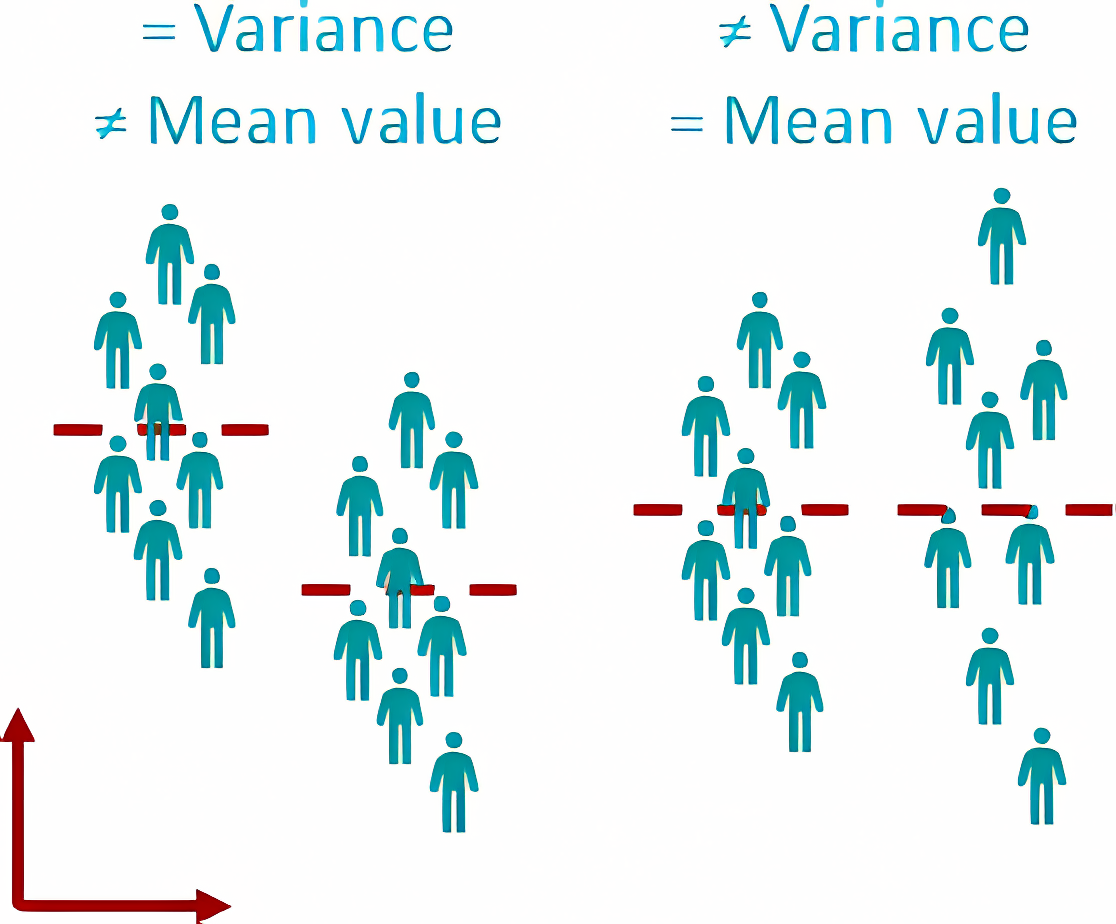
Teste t para duas amostras indep.
Independent-samples t test
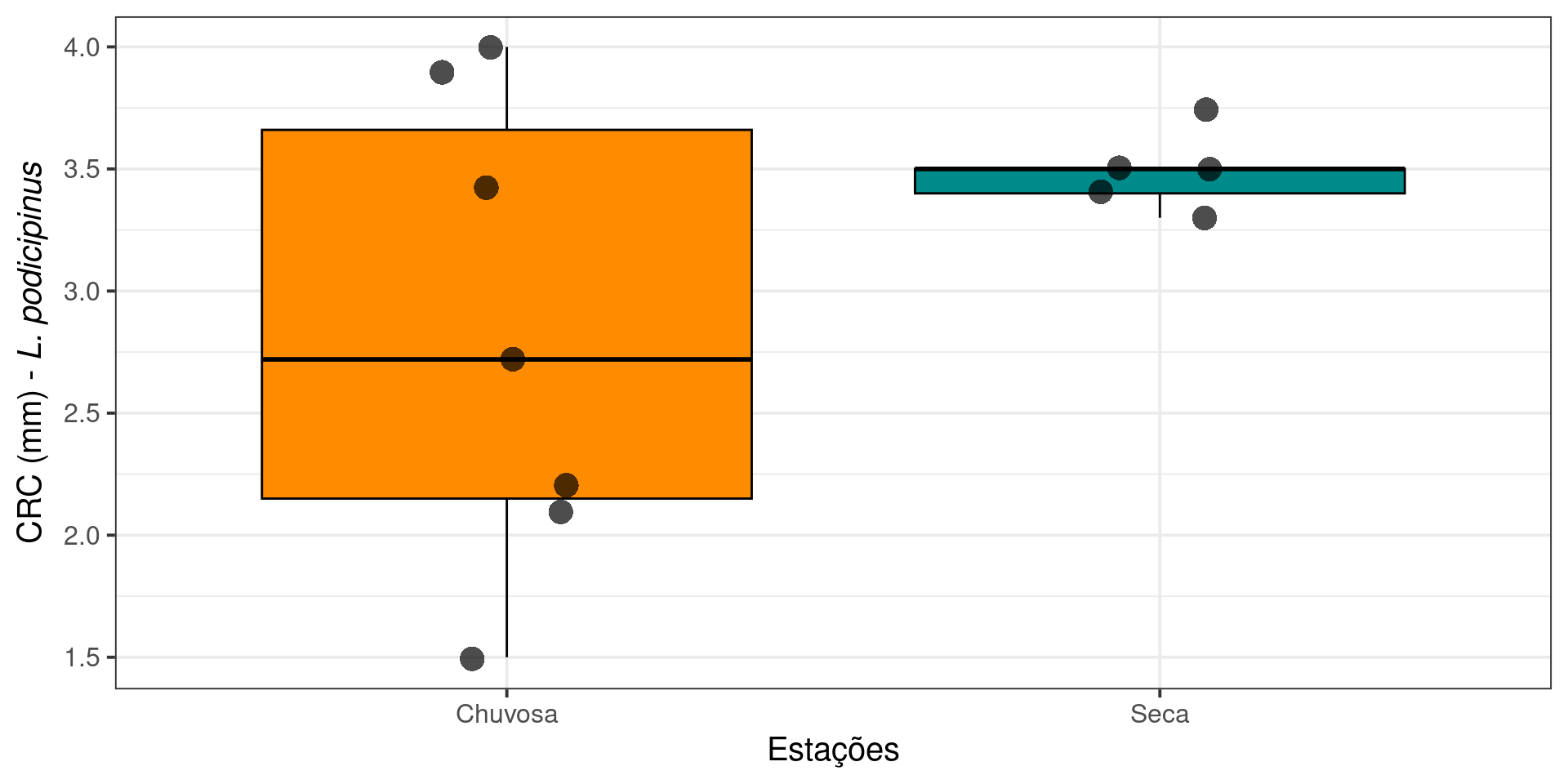
Leptodactylus podicipinus
Comprimento rostro-cloacal (CRC)

Teste t para duas amostras indep.
Independent-samples t test
| Estacao | mean | sd |
|---|---|---|
| Chuvosa | 2.83 | 0.96 |
| Seca | 3.49 | 0.17 |
Teste t para duas amostras indep.
Independent-samples t test
## Teste de normalidade dos residuos - H0: distribuicao dos residuos e normal
residuos <- residuals(lm(CRC ~ Estacao, data = teste_t_var_diferente))
shapiro.test(residuos)
Shapiro-Wilk normality test
data: residuos
W = 0.96272, p-value = 0.8219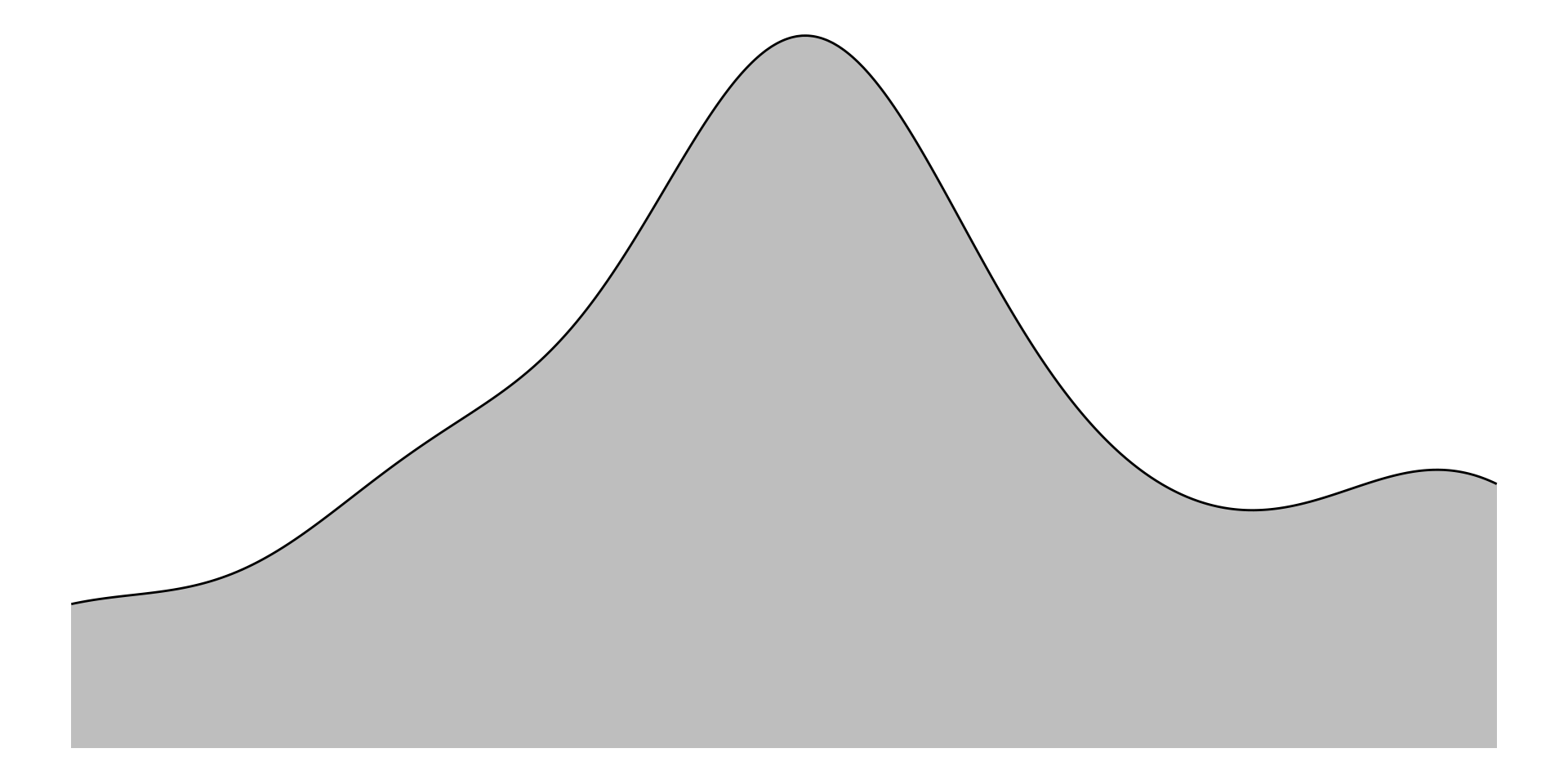
Teste t para duas amostras indep.
Independent-samples t test
## Teste de homogeneidade de variancia - H0: variancia e homogenea
car::leveneTest(CRC ~ as.factor(Estacao), data = teste_t_var_diferente)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 9.8527 0.01053 *
10
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Teste t para duas amostras indep.
Independent-samples t test
Teste t
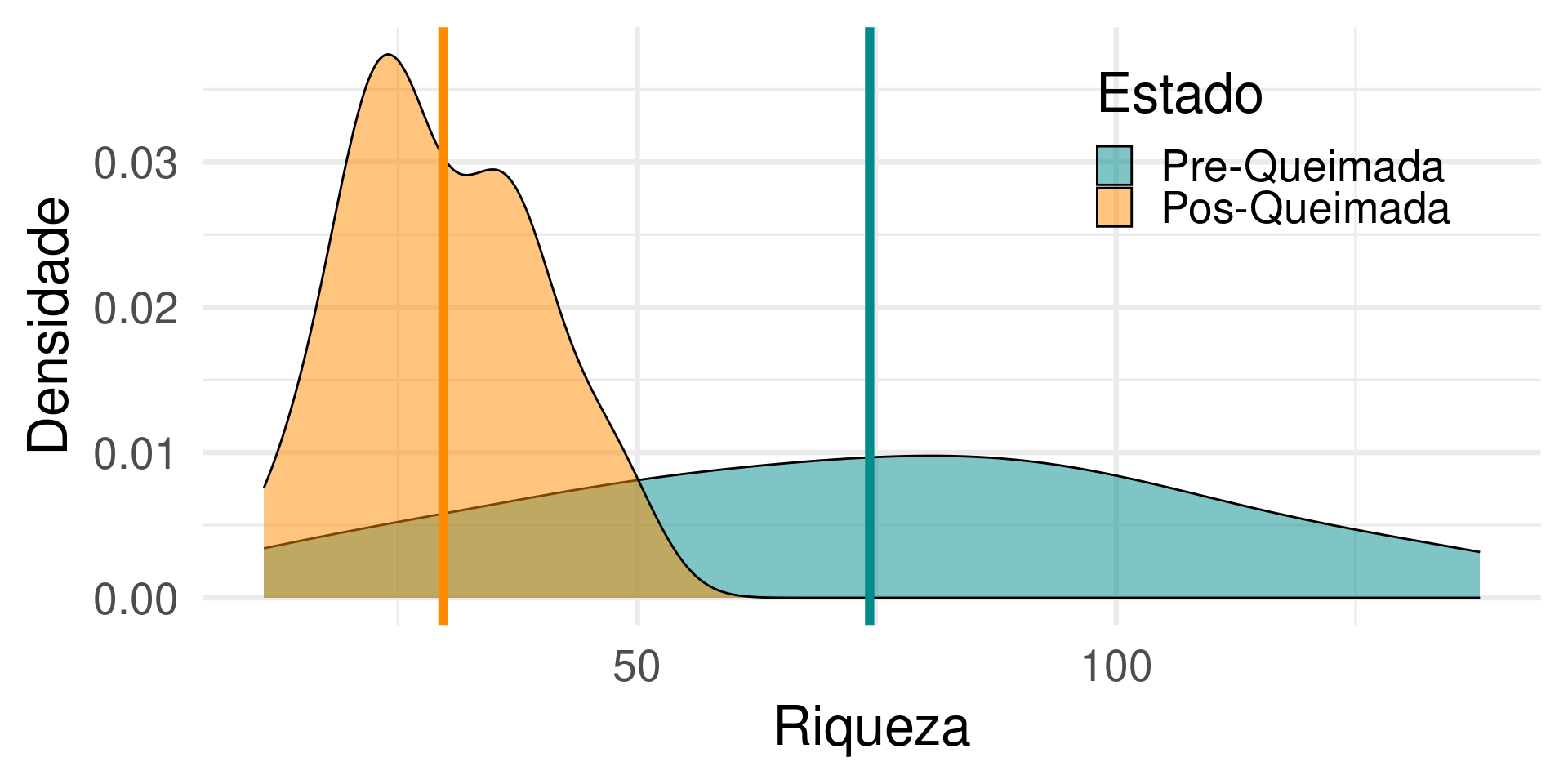
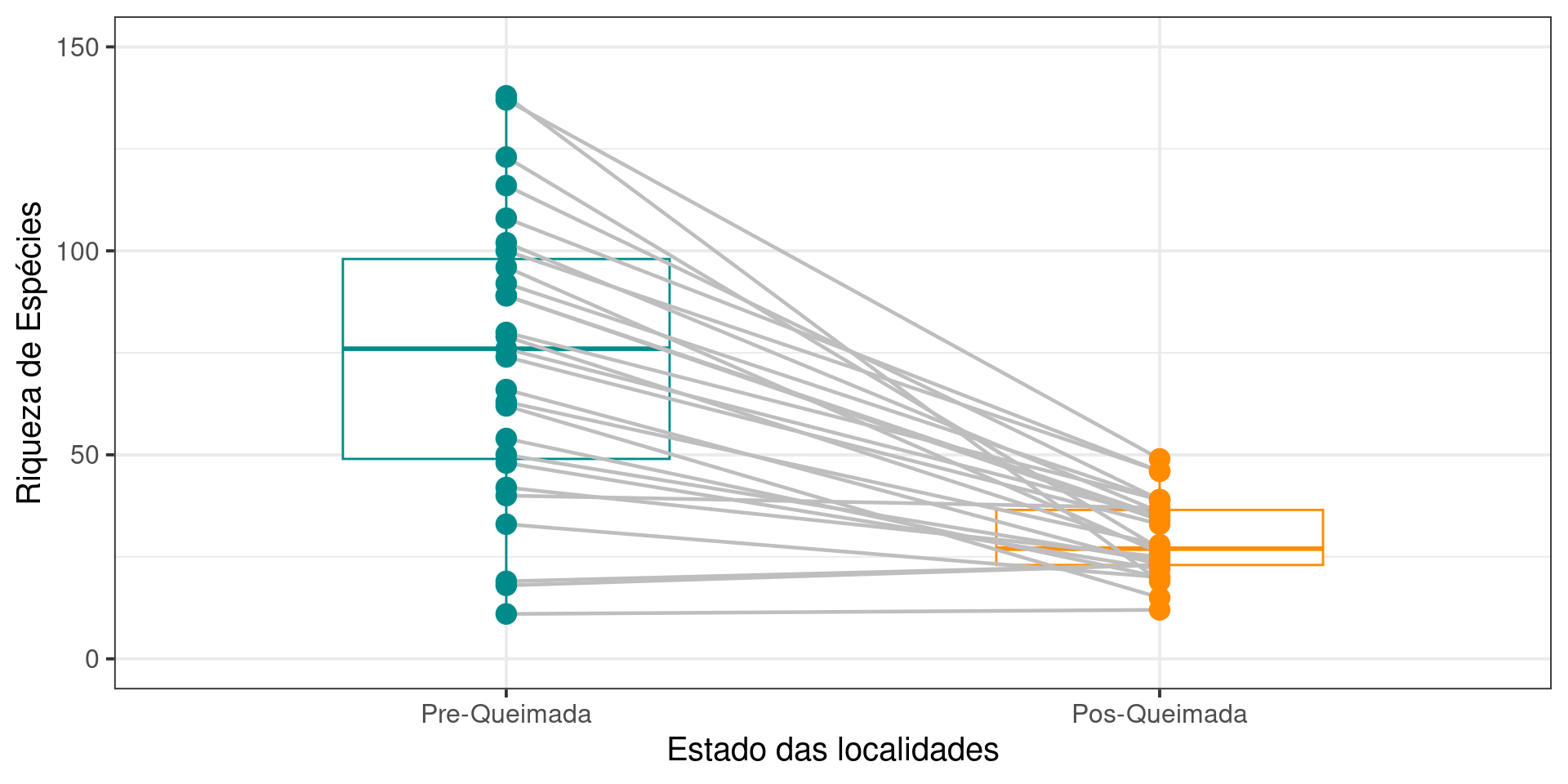
Área queimada
Número de espécies de artrópodes


Teste t para duas amostras pareadas
Paired-samples t test
| Estado | mean | sd |
|---|---|---|
| Pre-Queimada | 74.26 | 35.16 |
| Pos-Queimada | 29.70 | 9.71 |
Teste t para duas amostras indep.
Paired-samples t test
## Teste de normalidade dos residuos - H0: é normal
residuos <- residuals(lm(Riqueza ~ Estado, data = teste_t_pareado))
shapiro.test(residuos)
Shapiro-Wilk normality test
data: residuos
W = 0.96471, p-value = 0.1121
Teste t para duas amostras indep.
Paired-samples t test
## Teste de homogeneidade de variancia - H0: tem homogeneidade
car::leveneTest(Riqueza ~ as.factor(Estado), data = teste_t_pareado)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 26.138 4.64e-06 ***
52
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Teste t para duas amostras indep.
Paired-samples t test
Muito obrigado!


![]()